基于米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
2025年09月05日 17:31 发布者:swiftman
当 GPT-4o 用毫秒级响应处理图文混合指令、Gemini-1.5-Pro 以百万 token 上下文 “消化” 长文档时,行业的目光正从云端算力竞赛转向一个更实际的命题:如何让智能 “落地”?―― 摆脱网络依赖、保护本地隐私、控制硬件成本,让设备真正具备 “看见并对话” 的离线智能,成为边缘 AI 突破的核心卡点。如今,“端侧能否独立运行图文多轮对话” 已不再是技术疑问,而是工程实现问题。RK3576 通过硬件算力优化与软件栈协同,将视觉编码、语言推理、对话管理三大核心能力封装为可落地的工程方案,而本文将聚焦其多轮对话的部署全流程,拆解从模型加载到交互推理的每一个关键环节。
RK3576 多轮对话:基于历史回答图中女孩头发和衣服分别是什么颜色
一、引言1.1 什么是多轮对话?这种交互模式与单轮问答的区别在于:
[*]上下文依赖性:每轮对话需关联历史信息(如用户偏好、已确认的细节)。
[*]状态维护:系统需跟踪对话状态(如未完成的信息补全),避免重复询问或信息遗漏。
[*]动态意图调整:用户可能在对话中修正或细化需求,系统需实时调整响应策略
1.2 多轮对话系统鸟瞰:三颗“核心”协同驱动基于纯 C++实现,采用单线程事件循环机制,承担着对话流程的统筹调度工作,具体职责包括:
[*]多轮对话的 KV-Cache 维护与手动清除;
[*]Prompt 模板的动态渲染;
[*]用户输入的解析处理与推理结果的回显展示。
1.3 核心逻辑:多轮对话的处理流程该方案的多模态多轮对话 demo,整体遵循“模型加载 → 图片预处理 → 用户交互 → 推理输出”的核心流程,支持图文一体的多模态对话,适配多轮问答、视觉问答等典型场景。首先加载大语言模型(LLM),并配置模型路径、max_new_tokens(生成内容最大 token 数)、max_context_len(最大上下文长度)、top_k、特殊 token 等关键参数;随后加载视觉编码模型(imgenc),为后续图片处理做好准备。
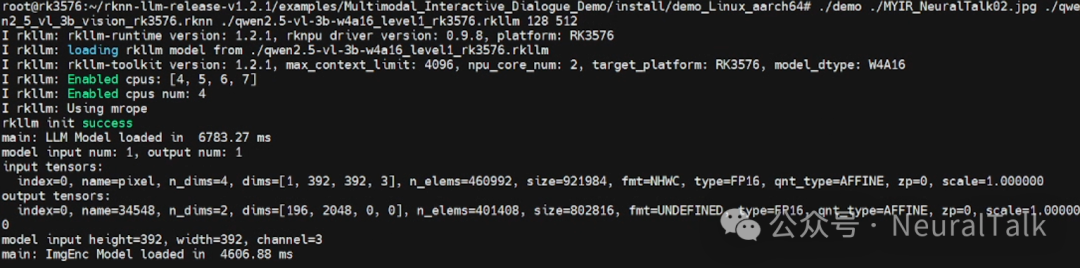
RK3576 平台运行多模态对话 Demo 的终端日志,显示视觉与语言模型成功加载,包含模型版本、硬件配置及张量信息,完成多模态交互前的初始化。
2. 图片处理与特征提取程序会提供预设问题供用户选择(官方案例中也有输入序号,可以快速提问),同时支持用户自定义输入,核心交互逻辑通过以下机制实现:
[*]上下文记忆
[*]通过设置rkllm_infer_params.keep_history = 1,开启上下文记忆功能,KV-Cache 在显存中持续追加存储,每轮对话仅计算新增 token,大幅提升推理效率。使模型能关联多轮对话内容;
[*]若设为 0,则每轮对话独立,不保留历史信息,详见src/main.cpp。
[*]历史缓存清空:当用户输入“clear”时,系统调用rkllm_clear_kv_cache(llmHandle, 1, nullptr, nullptr),清空模型的 KV 缓存,重置对话上下文。
[*]Prompt 工程:动态定义模型“人设”:采用三段式 Prompt 模板,通过rkllm_set_chat_template()动态注入模型,无需重新训练即可切换人设,支持中英文双语系统提示。
用户输入后,系统先判断输入中是否包含
通过 U 盘或者手机将编译好的产物文件、模型、图片上传到开发板上,然后在多轮对话的实例的目录下,执行以下命令:cd /data/demo_Linux_aarch64
export LD_LIBRARY_PATH=./lib
./demo demo.jpg vision.rknn llm.rkllm 128 512
以下面这张图片作为测试图片,选择下面这张图是因为,有人物、文字、物体、背景等。

测试图片2:图片背景是赛博风格
每轮对话我都有截动态图,可以感受下体感速度。

rkllm 模型加载 6.7 秒

视觉编码 rknn 模型进行处理,生成图片的 embedding 向量,完成图像特征的提取,4.5 秒
方案具备良好的可扩展性,便于开发者根据需求进行二次开发:
[*]替换视觉骨干:修改image_enc.cc文件,将输入分辨率调整为与模型匹配的大小,原因是这些参数与模型的固有结构设计和输入处理逻辑强绑定,直接影响特征提取的正确性和数据传递的一致性。不同的 Qwen2-VL 模型(2B 和 7B)需要代码中指定IMAGE_HEIGHT、IMAGE_WIDTH及EMBED_SIZE;
[*]微调 LLM 模型:借助 RKLLM 工具链的 LoRA-INT4 量化支持,在 24 GB 显存的 PC 上,30 分钟内可完成 2 亿参数模型的增量训练;
[*]接入语音能力:在main.cpp中集成 VAD(语音活动检测)+ ASR(语音识别,如 Whisper-Tiny INT8)模块,将语音转换为文本后接入现有推理流水线,实现“看图说话+语音问答”的融合交互。
五、结论与未来发展方向如果说 “大模型上云” 是 AI 的 “星辰大海”,那么 “多模态落地端侧” 就是 AI 的 “柴米油盐”―― 后者决定了智能技术能否真正渗透到智能家居、工业质检、穿戴设备等千万级场景中。RK3576 的多模态交互对话方案,其价值远不止 “实现了一项技术”,更在于提供了一套 “算力适配 - 工程封装 - 二次拓展” 的端侧 AI 落地范式。展望未来,这套方案的演进将围绕三个方向深化:
[*]其一,算力效率再突破―― 通过异步模型加载、NPU 与 CPU 协同调度,进一步压缩首轮推理延迟,适配对响应速度敏感的车载、医疗等场景;
[*]其二,多模态融合再升级―― 在图文基础上集成语音、传感器数据,实现 “看 + 听 + 感知” 的跨模态对话;
[*]其三,生态适配再拓展―― 支持更多开源多模态模型的快速移植,形成 “芯片 - 工具链 - 模型” 的协同生态。
参考资料airockchip/rknn-llm: 'https://github.com/airockchip/rknn-llm'