为什么以及如何将Efinix FPGA用于AI/ML成像第2部分:图像采集和处理
2023年05月24日 15:00 发布者:eechina
来源:Digi-Key作者:Adam Taylor
编者按:全新的 FPGA 架构方法带来了更精细的控制和更大的灵活性,以满足机器学习 (ML) 和人工智能 (AI) 的需求。本系列文章包括两部分,第 1 部分介绍了 Efinix 一款此类架构的产品,以及如何借助开发板开始使用该产品。本文是第 2 部分,讨论了开发板与外部器件和外设(如摄像头)的连接,以及如何利用 FPGA 消除图像处理的瓶颈。
从工业控制和安全到机器人、航空航天和汽车,FPGA 在许多应用中扮演着重要角色。凭借可编程逻辑内核的灵活性及其广泛的接口能力,FPGA 在可以部署机器学习 (ML) 的影像处理中的应用日渐广泛。由于其并行逻辑结构,FPGA 非常适合用来实现具有多个高速摄像头接口的解决方案。此外,FPGA 还能在逻辑中使用专门的处理管道,从而消除与基于 CPU 或 GPU 的解决方案相关的共享资源瓶颈。
本文将再次介绍 Efinix 的 Titanium FPGA,并探讨该 FPGA 的 Ti180 M484 开发板附带的参考图像处理应用。其目的是了解设计的构成部分,并明确 FPGA 技术能够消除哪些方面的瓶颈或为开发人员带来其他好处。
基于 Ti180 M484 的参考设计
从概念上看,该参考设计(图 1)接收来自几个移动行业处理器接口 (MIPI) 摄像头的图像,在 LPDDR4x 中执行帧缓冲,然后将图像输出到高清多媒体接口 (HDMI) 显示器。利用一个 FPGA 夹层卡 (FMC) 和开发板上的四个 Samtec QSE 接口提供摄像头输入和 HDMI 输出。
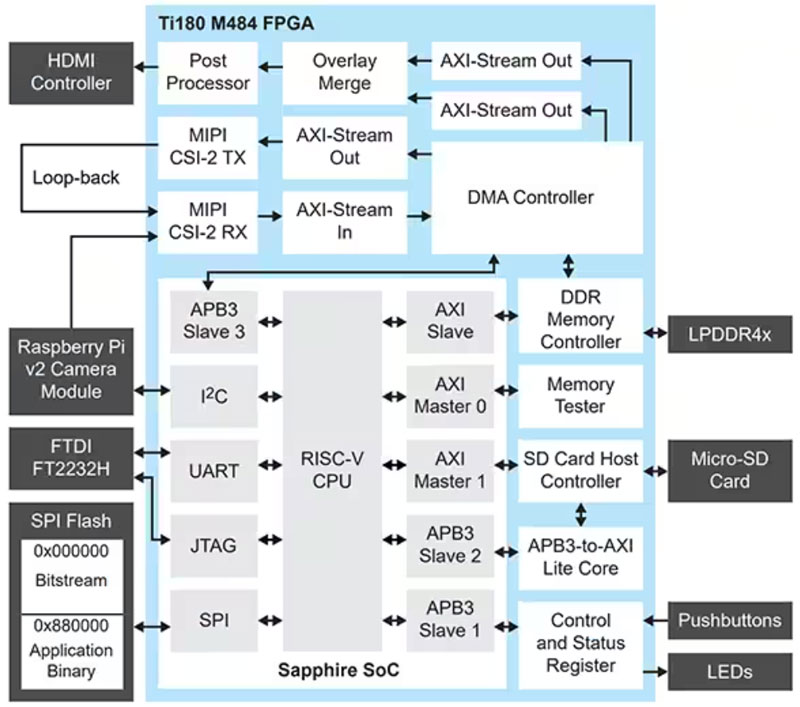
图 1:从概念上看,Ti180 M484 参考设计接收来自几个 MIPI 摄像头的图像,在 LPDDR4x 中执行帧缓冲,然后将图像输出到 HDMI 显示器。>(图片来源:Efinix)
FMC 转 QSE 扩展卡与 HDMI 子卡配合使用,提供输出视频路径,而 3 个 QSE 连接器用于与 DFRobot SEN0494 MIPI 摄像头连接。如果没有多个 MIPI 摄像头,可以使用单个摄像头,通过回环单个摄像头通道来模拟其他摄像头。
从高层次看,这种应用可能看起来很简单。但是要以高帧率接收多个高清 (HD) MIPI 流颇具挑战性。这恰好是 FPGA 技术的优势所在,因为它允许设计人员并行利用多个 MIPI 流。
该参考设计的架构利用了 FPGA 的并行和顺序处理结构。并行结构用于实现图像处理管道,而 RISC-V 处理器提供用于 FPGA 查询表 (LUT) 的顺序处理。
在许多基于 FPGA 的图像处理系统中,图像处理管道可以分成两个部分,即输入和输出流。输入流连接到摄像头/传感器接口,各种处理功能则应用至传感器输出。这些处理功能包括 Bayer 转换、自动白平衡和其他增强功能。在输出流中,准备图像用于显示。这包括改变颜色空间(例如从 RGB 更改为 YUV),以及后处理为所需的输出格式,如 HDMI。
通常,输入图像处理链以传感器的像素时钟频率运行。这与输出链的时序不同,输出链以输出显示频率进行处理。
帧缓冲区用于连接输入和输出处理管道,它通常存储在 LPDDR4x 等外部高性能存储器中。该帧缓冲区在输入和输出管道之间去耦,从而允许以适当的时钟频率通过直接内存访问来访问帧缓冲区。
Ti180 参考设计采用了与上述概念类似的方法。输入图像处理管道实现了一个 MIPI 摄像头串行接口 2 (CSI-2) 接收器知识产权 (IP) 内核,该内核建立在支持 MIPI 物理层 (MIPI D-PHY) 的 Titanium FPGA 输入/输出 (I/O) 之上。MIPI 接口颇为复杂,因为除了低速和高速通信,它还在同一差分对上同时使用单端和差分信号。将 MIPI D-PHY 集成到 FPGA I/O 中,降低了电路板设计的复杂性,同时还可简化物料清单 (BOM)。
收到摄像头的图像流后,参考设计会将 MIPI CSI-2 RX 的输出转换为高级可扩展接口 (AXI) 流。AXI 流属于单向高速接口,提供从主设备到从设备的数据流。除了在主设备和从设备之间传输的握手信号(tvalid 和 tready),还提供了边带信号。这些边带信号可用于传递图像时序信息,如帧的开始和行的结束。
AXI 流是图像处理应用的理想选择,使 Efinix 能够提供一系列的图像处理 IP,然后可以根据应用的需要轻松集成到处理链中。
接收后,MIPI CSI-2 图像数据和时序信号被转换为 AXI 流,并输入到直接内存访问 (DMA) 模块,该模块将图像帧写入 LPDDR4x 并充当帧缓冲区。
此 DMA 模块在 Sapphire 片上系统 (SoC) 内 FPGA 中的 RISC-V 内核控制下运行。该 SoC 提供停止和开始 DMA 写入等控制功能,此外还为 DMA 写入通道提供必要的信息,以便将图像数据正确写入 LPDDR4x。这包括有关存储器位置的信息以及图像宽度和高度(以字节为单位)。
该参考设计中的输出通道在 RISC-V SoC 的控制下从 LPDDR4x 帧缓冲区读取图像信息。数据作为 AXI 流从 DMA IP 输出,然后从传感器提供的 RAW 格式转换为 RGB 格式(图 2),并准备通过板载 Analog Devices 的 ADV7511 HDMI 发射器输出。

图 2:参考设计输出的样本图像。(图片来源:Adam Taylor)
借助 DMA,Sapphire SoC RISC-V 也能够访问存储于帧缓冲区中的图像,以及统计和图像信息摘要。Sapphire SoC 还能将覆盖层写入 LPDDR4x 中,以便与输出的视频流合并。
现代 CMOS 图像传感器 (CIS) 有几种工作模式,可配置为提供片上处理,以及几种不同的输出格式和时钟方案。通常通过 I²C 接口提供这种配置。在该 Efinix 参考设计中,与 MIPI 摄像头的 I²C 通信由 Sapphire SoC RISC-V 处理器提供。
在 Titanium FPGA 中集成 RISC-V 处理器减少了最终解决方案的整体尺寸,因为不需要部署会增加设计风险的复杂 FPGA 状态机,也不需要会增加 BOM 的外部处理器。
集成该处理器后,还可以支持额外的 IP 与 MicroSD 卡进行通信。这能够支持可能需要存储图像以供日后分析的现实应用。
总的来说,Ti180 参考设计的架构经过优化,可实现紧凑、低成本但高性能的解决方案,使开发人员能够通过系统集成降低 BOM 成本。
参考设计的主要优点之一是可用于在定制硬件上启动应用开发,使开发人员能够利用设计的关键元素,并以此为基础进行所需的定制。这包括能够利用 Efinix 的 TinyML 流程来实现运行于 FPGA 上的视觉 TinyML 应用。这既可利用 FPGA 逻辑的并行特性,又可轻松地将自定义指令添加至 RISC-V 处理器中,从而能够在 FPGA 逻辑内创建加速器。
实现
正如第 1 部分所述,Efinix 架构的独特之处在于,它使用可交换逻辑和路由 (XLR) 单元来提供路由和逻辑功能。像上述参考设计这样的视频系统属于逻辑和路由都很复杂的混合系统:需要大量的逻辑来实现图像处理功能,还需要广泛的路由来以所需的频率连接 IP 单元。
该参考设计使用了器件内约 42% 的 XLR 单元,留下了充足的空间来添加内容,包括边缘 ML 等定制应用。
块 RAM 和数字信号处理 (DSP) 块的使用也非常高效,只使用了 640 个 DSP 块中的 4 个和 40% 的存储块(图 3)。
内核资源
输入 1264 / 3706
输出 1725 / 4655
XLR 73587 / 172800
存储块 508 / 1280
DSP 块 4 / 640
图 3:Efinix 架构上的资源分配显示,仅使用了 42% 的 XLR 单元,为其他进程预留了充足的空间。(图片来源:Adam Taylor)
在器件 IO 上,LPDDR4x 的 DDR 接口用于为 Sapphire SoC 提供应用存储器以及提供图像帧缓冲区。所有器件专用的 MIPI 资源与 50% 的锁相环一起使用(图 4)。
外设资源
DDR 1 / 1
GPIO 22 / 27
HSIO 20.0 / 59
JTAG 用户 TAP 1 / 4
MIPI RX 4 / 4
MIPI TX 4 / 4
振荡器 0 / 1
PLL 4 / 8
图 4:所用接口和 I/O 资源的快照。(图片来源:Adam Taylor)
通用 I/O (GPIO) 用于提供 I²C 通信以及几个连接到 Sapphire SoC 的接口,包括 NOR FLASH、USB UART 和 SD 卡。HSIO 用于向 ADC7511 HDMI 发射器提供高速视频输出。
采用 FPGA 进行设计的一个关键因素是,不仅要在 FPGA 中实现和拟合设计,还要能够在 FPGA 内放置逻辑设计,并在路由时达到所需的时序性能。
单时钟域 FPGA 设计的时代已经一去不复返了。在 Ti180 参考设计中,有几个不同的时钟,都以高频率运行。最终时序表显示了系统内时钟达到的最大频率。在此表中也可以看到时钟约束中要求的时序性能(图 5),其中 HDMI 输出时钟的最大时钟频率为 148.5 MHz。

图 5:参考设计的时钟约束。(图片来源:Adam Taylor)
针对时钟约束的时序实现显示了 Titanium FPGA XLR 结构的潜力,因为它减少了可能的路由延迟,从而提高了设计性能(图 6)。
时序
最差负时序裕量 (WNS) 0.182 ns
最差保持时序裕量 (WHS) 0.026 ns
i_pixel_clk 211.909 MHz
tx_escclk 261.370 MHz
i_pixel_clk_tx 210.881 MHz
i_sys_clk 755.858 MHz
i_axi0_mem_clk 130.429 MHz
i_sys_clk_25mhz 234.577 MHz
i_soc_clk 187.231 MHz
i_hdmi_clk 233.918 MHz
mipi_dphy_rx_inst1_WORD_CLKOUT_HS 273.973 MHz
mipi_dphy_rx_inst2_WORD_CLKOUT_HS 262.881 MHz
mipi_dphy_rx_inst3_WORD_CLKOUT_HS 204.290 MHz
mipi_dphy_rx_inst4_WORD_CLKOUT_HS 207.598 MHz
mipi_dphy_tx_inst1_SLOWCLK 201.979 MHz
mipi_dphy_tx_inst2_SLOWCLK 191.865 MHz
mipi_dphy_tx_inst3_SLOWCLK 165.235 MHz
mipi_dphy_tx_inst4_SLOWCLK 160.823 MHz
jtag_inst1_TCK 180.505 MHz
图 6:针对时钟约束的时序实现显示了 Titanium FPGA XLR 结构的潜力,能够减少可能的路由延迟,从而提高设计性能。(图片来源:Adam Taylor)
总结
Ti180 M484 参考设计清楚地展示了 Efinix FPGA 的能力,尤其是 Ti180。该设计利用几个独特的 I/O 结构来实现复杂的图像处理路径,支持多个传入的 MIPI 流。此图像处理系统在软核 Sapphire SoC 的控制下运行,实现了该应用必需的顺序处理元素。