清华发布最通俗易懂的AI芯片研究报告
2018年11月27日 14:40 发布者:eechina
一、AI芯片基本知识及现状从广义上讲只要能够运行人工智能算法的芯片都叫作 AI 芯片。但是通常意义上的 AI 芯片指的是针对人工智能算法做了特殊加速设计的芯片, 现阶段, 这些人工智能算法一般以深度学习算法为主,也可以包括其它机器学习算法。 人工智能与深度学习的关系如图所示。
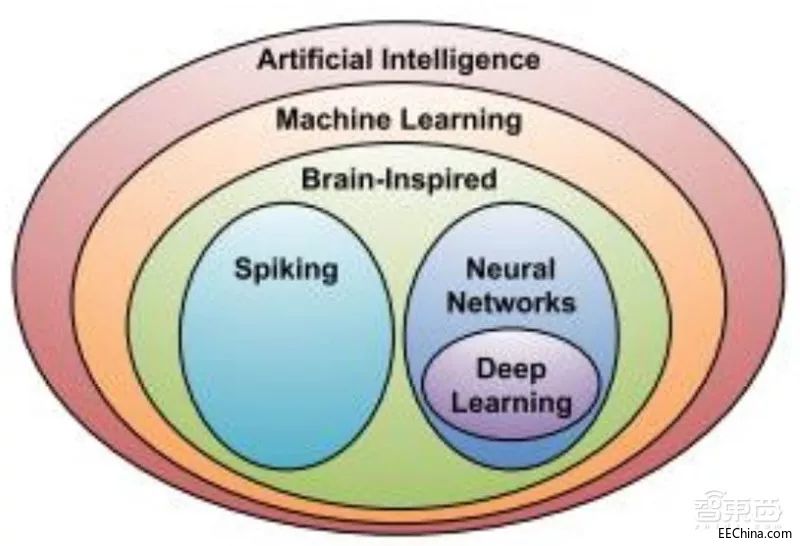
▲人工智能与深度学习
深度学习算法,通常是基于接收到的连续数值, 通过学习处理, 并输出连续数值的过程,实质上并不能完全模仿生物大脑的运作机制。 基于这一现实, 研究界还提出了SNN(Spiking Neural Network,脉冲神经网络) 模型。 作为第三代神经网络模型, SNN 更贴近生物神经网络――除了神经元和突触模型更贴近生物神经元与突触之外, SNN 还将时域信息引入了计算模型。目前基于 SNN 的 AI 芯片主要以 IBM 的 TrueNorth、 Intel 的 Loihi 以及国内的清华大学天机芯为代表。
1、AI 芯片发展历程
从图灵的论文《计算机器与智能》 和图灵测试, 到最初级的神经元模拟单元――感知机, 再到现在多达上百层的深度神经网络,人类对人工智能的探索从来就没有停止过。 上世纪八十年代,多层神经网络和反向传播算法的出现给人工智能行业点燃了新的火花。反向传播的主要创新在于能将信息输出和目标输出之间的误差通过多层网络往前一级迭代反馈,将最终的输出收敛到某一个目标范围之内。 1989 年贝尔实验室成功利用反向传播算法,在多层神经网络开发了一个手写邮编识别器。 1998 年 Yann LeCun 和 Yoshua Bengio 发表了手写识别神经网络和反向传播优化相关的论文《Gradient-based learning applied to documentrecognition》,开创了卷积神经网络的时代。
此后, 人工智能陷入了长时间的发展沉寂阶段,直到 1997年 IBM的深蓝战胜国际象棋大师和 2011年 IBM的沃森智能系统在 Jeopardy节目中胜出,人工智能才又一次为人们所关注。 2016 年 Alpha Go 击败韩国围棋九段职业选手,则标志着人工智能的又一波高潮。从基础算法、 底层硬件、 工具框架到实际应用场景, 现阶段的人工智能领域已经全面开花。
作为人工智能核心的底层硬件 AI 芯片,也同样经历了多次的起伏和波折,总体看来,AI 芯片的发展前后经历了四次大的变化,其发展历程如图所示。

▲AI 芯片发展历程
(1) 2007 年以前, AI 芯片产业一直没有发展成为成熟的产业; 同时由于当时算法、数据量等因素, 这个阶段 AI 芯片并没有特别强烈的市场需求,通用的 CPU 芯片即可满足应用需要。
(2) 随着高清视频、 VR、 AR游戏等行业的发展, GPU产品取得快速的突破; 同时人们发现 GPU 的并行计算特性恰好适应人工智能算法及大数据并行计算的需求,如 GPU 比之前传统的 CPU在深度学习算法的运算上可以提高几十倍的效率,因此开始尝试使用 GPU进行人工智能计算。
(3) 进入 2010 年后,云计算广泛推广,人工智能的研究人员可以通过云计算借助大量 CPU 和 GPU 进行混合运算,进一步推进了 AI 芯片的深入应用,从而催生了各类 AI 芯片的研发与应用。
(4) 人工智能对于计算能力的要求不断快速地提升,进入 2015 年后, GPU 性能功耗比不高的特点使其在工作适用场合受到多种限制, 业界开始研发针对人工智能的专用芯片,以期通过更好的硬件和芯片架构,在计算效率、能耗比等性能上得到进一步提升。
2、我国 AI 芯片发展情况
目前,我国的人工智能芯片行业发展尚处于起步阶段。 长期以来,中国在 CPU、 GPU、DSP 处理器设计上一直处于追赶地位,绝大部分芯片设计企业依靠国外的 IP 核设计芯片,在自主创新上受到了极大的限制。 然而,人工智能的兴起,无疑为中国在处理器领域实现弯道超车提供了绝佳的机遇。 人工智能领域的应用目前还处于面向行业应用阶段,生态上尚未形成垄断,国产处理器厂商与国外竞争对手在人工智能这一全新赛场上处在同一起跑线上,因此, 基于新兴技术和应用市场,中国在建立人工智能生态圈方面将大有可为。
由于我国特殊的环境和市场,国内 AI 芯片的发展目前呈现出百花齐放、百家争鸣的态势, AI 芯片的应用领域也遍布股票交易、金融、商品推荐、安防、早教机器人以及无人驾驶等众多领域,催生了大量的人工智能芯片创业公司,如地平线、深鉴科技、中科寒武纪等。
尽管如此, 国内公司却并未如国外大公司一样形成市场规模, 反而出现各自为政的散裂发展现状。除了新兴创业公司,国内研究机构如北京大学、清华大学、中国科学院等在AI 芯片领域都有深入研究;而其他公司如百度和比特大陆等, 2017 年也有一些成果发布。可以预见,未来谁先在人工智能领域掌握了生态系统,谁就掌握住了这个产业的主动权。
3、AI学者概况
基于来自清华大学AMiner 人才库数据,全球人工智能芯片领域学者分布如图所示, 从图中可以看到, 人工智能芯片领域的学者主要分布在北美洲,其次是欧洲。 中国对人工智能芯片的研究紧跟其后,南美洲、非洲和大洋洲人才相对比较匮乏。

▲ 人工智能芯片领域研究学者全球分布
按国家进行统计来看美国是人工智能芯片领域科技发展的核心。 英国的人数紧排在美国之后。其他的专家主要分布在中国、 德国、 加拿大、意大利和日本 。

▲人工智能芯片领域研究学者全球分布
对全球人工智能芯片领域最具影响力的 1000 人的迁徙路径进行了统计分析,得出下图所示的各国人才逆顺差对比。
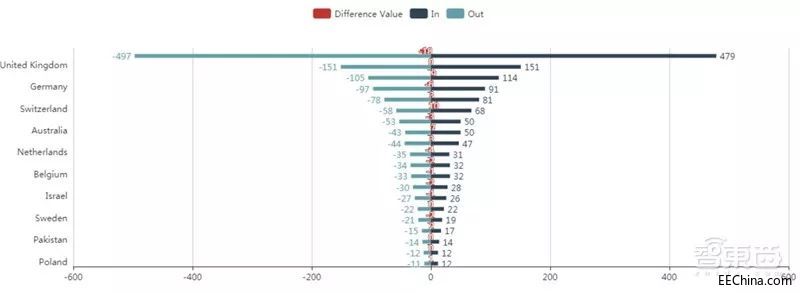
▲各国人才逆顺差
可以看出,各国人才的流失和引进是相对比较均衡的,其中美国为人才流动大国,人才输入和输出幅度都大幅度领先。英国、 中国、 德国和瑞士等国次于美国,但各国之间人才流动相差并不明显。
二、AI 芯片的分类及技术
人工智能芯片目前有两种发展路径:一种是延续传统计算架构,加速硬件计算能力,主要以 3 种类型的芯片为代表,即 GPU、 FPGA、 ASIC,但 CPU依旧发挥着不可替代的作用;另一种是颠覆经典的冯・诺依曼计算架构,采用类脑神经结构来提升计算能力, 以 IBM TrueNorth 芯片为代表。
1、传统 CPU
计算机工业从 1960 年代早期开始使用 CPU 这个术语。迄今为止, CPU 从形态、设计到实现都已发生了巨大的变化,但是其基本工作原理却一直没有大的改变。 通常 CPU 由控制器和运算器这两个主要部件组成。 传统的 CPU 内部结构图如图 3 所示, 从图中我们可以看到:实质上仅单独的 ALU 模块(逻辑运算单元)是用来完成数据计算的,其他各个模块的存在都是为了保证指令能够一条接一条的有序执行。这种通用性结构对于传统的编程计算模式非常适合,同时可以通过提升 CPU 主频(提升单位时间内执行指令的条数)来提升计算速度。 但对于深度学习中的并不需要太多的程序指令、 却需要海量数据运算的计算需求, 这种结构就显得有些力不从心。尤其是在功耗限制下, 无法通过无限制的提升 CPU 和内存的工作频率来加快指令执行速度, 这种情况导致 CPU 系统的发展遇到不可逾越的瓶颈。

▲传统 CPU 内部结构图(仅 ALU 为主要计算模块)
2、并行加速计算的 GPU
GPU 作为最早从事并行加速计算的处理器,相比 CPU 速度快, 同时比其他加速器芯片编程灵活简单。
传统的 CPU 之所以不适合人工智能算法的执行,主要原因在于其计算指令遵循串行执行的方式,没能发挥出芯片的全部潜力。与之不同的是, GPU 具有高并行结构,在处理图形数据和复杂算法方面拥有比 CPU 更高的效率。对比 GPU 和 CPU 在结构上的差异, CPU大部分面积为控制器和寄存器,而 GPU 拥有更ALU(ARITHMETIC LOGIC UNIT,逻辑运算单元)用于数据处理,这样的结构适合对密集型数据进行并行处理, CPU 与 GPU 的结构对比如图 所示。程序在 GPU系统上的运行速度相较于单核 CPU往往提升几十倍乃至上千倍。随着英伟达、 AMD 等公司不断推进其对 GPU 大规模并行架构的支持,面向通用计算的 GPU(即GPGPU, GENERAL PURPOSE GPU,通用计算图形处理器)已成为加速可并行应用程序的重要手段。
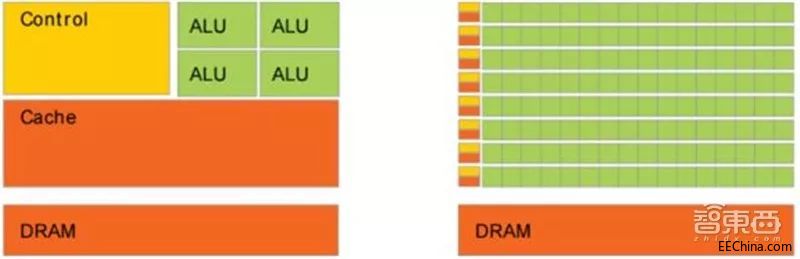
▲CPU 及 GPU 结构对比图(引用自 NVIDIA CUDA 文档)
GPU 的发展历程可分为 3 个阶段, 发展历程如图所示:
第 一 代 GPU(1999 年 以 前 ) , 部 分 功 能 从 CPU 分 离 , 实 现 硬 件 加 速 , 以GE(GEOMETRY ENGINE)为代表,只能起到 3D 图像处理的加速作用,不具有软件编程特性。
第二代 GPU(1999-2005 年), 实现进一步的硬件加速和有限的编程性。 1999 年,英伟达发布了“专为执行复杂的数学和几何计算的” GeForce256 图像处理芯片,将更多的晶体管用作执行单元, 而不是像 CPU 那样用作复杂的控制单元和缓存,将 T&L(TRANSFORM AND LIGHTING)等功能从 CPU 分离出来,实现了快速变换,这成为 GPU 真正出现的标志。之后几年, GPU 技术快速发展,运算速度迅速超过 CPU。 2001 年英伟达和 ATI 分别推出的GEFORCE3 和 RADEON 8500,图形硬件的流水线被定义为流处理器,出现了顶点级可编程性,同时像素级也具有有限的编程性,但 GPU 的整体编程性仍然比较有限。
第三代 GPU(2006年以后), GPU实现方便的编程环境创建, 可以直接编写程序。 2006年英伟达与 ATI分别推出了 CUDA(Compute United Device Architecture,计算统一设备架构)编程环境和 CTM(CLOSE TO THE METAL)编程环境, 使得 GPU 打破图形语言的局限成为真正的并行数据处理超级加速器。
2008 年,苹果公司提出一个通用的并行计算编程平台 OPENCL(OPEN COMPUTING LANGUAGE,开放运算语言),与 CUDA 绑定在英伟达的显卡上不同,OPENCL 和具体的计算设备无关。

▲GPU 芯片的发展阶段
目前, GPU 已经发展到较为成熟的阶段。谷歌、 FACEBOOK、微软、 TWITTER 和百度等公司都在使用 GPU 分析图片、视频和音频文件,以改进搜索和图像标签等应用功能。此外,很多汽车生产商也在使用 GPU 芯片发展无人驾驶。 不仅如此, GPU 也被应用于VR/AR 相关的产业。
但是 GPU也有一定的局限性。 深度学习算法分为训练和推断两部分, GPU 平台在算法训练上非常高效。但在推断中对于单项输入进行处理的时候,并行计算的优势不能完全发挥出来。
3、半定制化的 FPGA
FPGA 是在 PAL、 GAL、 CPLD 等可编程器件基础上进一步发展的产物。用户可以通过烧入 FPGA 配置文件来定义这些门电路以及存储器之间的连线。这种烧入不是一次性的,比如用户可以把 FPGA 配置成一个微控制器 MCU,使用完毕后可以编辑配置文件把同一个FPGA 配置成一个音频编解码器。因此, 它既解决了定制电路灵活性的不足,又克服了原有可编程器件门电路数有限的缺点。
FPGA 可同时进行数据并行和任务并行计算,在处理特定应用时有更加明显的效率提升。对于某个特定运算,通用 CPU 可能需要多个时钟周期; 而 FPGA 可以通过编程重组电路,直接生成专用电路,仅消耗少量甚至一次时钟周期就可完成运算。
此外,由于 FPGA的灵活性,很多使用通用处理器或 ASIC难以实现的底层硬件控制操作技术, 利用 FPGA 可以很方便的实现。这个特性为算法的功能实现和优化留出了更大空间。同时 FPGA 一次性成本(光刻掩模制作成本)远低于 ASIC,在芯片需求还未成规模、深度学习算法暂未稳定, 需要不断迭代改进的情况下,利用 FPGA 芯片具备可重构的特性来实现半定制的人工智能芯片是最佳选择之一。
功耗方面,从体系结构而言, FPGA 也具有天生的优势。传统的冯氏结构中,执行单元(如 CPU 核)执行任意指令,都需要有指令存储器、译码器、各种指令的运算器及分支跳转处理逻辑参与运行, 而 FPGA 每个逻辑单元的功能在重编程(即烧入)时就已经确定,不需要指令,无需共享内存,从而可以极大的降低单位执行的功耗,提高整体的能耗比。
由于 FPGA 具备灵活快速的特点, 因此在众多领域都有替代 ASIC 的趋势。 FPGA 在人工智能领域的应用如图所示。

▲FPGA 在人工智能领域的应用
4、全定制化的 ASIC
目前以深度学习为代表的人工智能计算需求,主要采用 GPU、 FPGA 等已有的适合并行计算的通用芯片来实现加速。在产业应用没有大规模兴起之时,使用这类已有的通用芯片可以避免专门研发定制芯片(ASIC) 的高投入和高风险。但是,由于这类通用芯片设计初衷并非专门针对深度学习,因而天然存在性能、 功耗等方面的局限性。随着人工智能应用规模的扩大,这类问题日益突显。
GPU 作为图像处理器, 设计初衷是为了应对图像处理中的大规模并行计算。因此,在应用于深度学习算法时,有三个方面的局限性:第一,应用过程中无法充分发挥并行计算优势。 深度学习包含训练和推断两个计算环节, GPU 在深度学习算法训练上非常高效, 但对于单一输入进行推断的场合, 并行度的优势不能完全发挥。 第二, 无法灵活配置硬件结构。 GPU 采用 SIMT 计算模式, 硬件结构相对固定。 目前深度学习算法还未完全稳定,若深度学习算法发生大的变化, GPU 无法像 FPGA 一样可以灵活的配制硬件结构。 第三,运行深度学习算法能效低于 FPGA。
尽管 FPGA 倍受看好,甚至新一代百度大脑也是基于 FPGA 平台研发,但其毕竟不是专门为了适用深度学习算法而研发,实际应用中也存在诸多局限:第一,基本单元的计算能力有限。为了实现可重构特性, FPGA 内部有大量极细粒度的基本单元,但是每个单元的计算能力(主要依靠 LUT 查找表)都远远低于 CPU 和 GPU 中的 ALU 模块; 第二、 计算资源占比相对较低。 为实现可重构特性, FPGA 内部大量资源被用于可配置的片上路由与连线; 第三,速度和功耗相对专用定制芯片(ASIC)仍然存在不小差距; 第四, FPGA 价格较为昂贵,在规模放量的情况下单块 FPGA 的成本要远高于专用定制芯片。
因此,随着人工智能算法和应用技术的日益发展,以及人工智能专用芯片 ASIC产业环境的逐渐成熟, 全定制化人工智能 ASIC也逐步体现出自身的优势,从事此类芯片研发与应用的国内外比较有代表性的公司如图所示。

▲人工智能专用芯片(包括类脑芯片) 研发情况一览
深度学习算法稳定后, AI 芯片可采用 ASIC 设计方法进行全定制, 使性能、功耗和面积等指标面向深度学习算法做到最优。
5、类脑芯片
类脑芯片不采用经典的冯・诺依曼架构, 而是基于神经形态架构设计,以 IBM Truenorth为代表。 IBM 研究人员将存储单元作为突触、计算单元作为神经元、传输单元作为轴突搭建了神经芯片的原型。目前, Truenorth 用三星 28nm 功耗工艺技术,由 54 亿个晶体管组成的芯片构成的片上网络有 4096 个神经突触核心,实时作业功耗仅为 70mW。由于神经突触要求权重可变且要有记忆功能, IBM 采用与 CMOS 工艺兼容的相变非挥发存储器(PCM)的技术实验性的实现了新型突触,加快了商业化进程。
三、AI芯片产业及趋势
1、AI芯片应用领域
随着人工智能芯片的持续发展,应用领域会随时间推移而不断向多维方向发展,这里我们选择目前发展比较集中的几个行业做相关的介绍。

▲AI芯片目前比较集中的应用领域
(1)智能手机
2017 年 9 月,华为在德国柏林消费电子展发布了麒麟 970 芯片,该芯片搭载了寒武纪的 NPU,成为“全球首款智能手机移动端 AI 芯片” ; 2017 年 10 月中旬 Mate10 系列新品(该系列手机的处理器为麒麟 970)上市。搭载了 NPU 的华为 Mate10 系列智能手机具备了较强的深度学习、本地端推断能力,让各类基于深度神经网络的摄影、图像处理应用能够为用户提供更加完美的体验。
而苹果发布以 iPhone X 为代表的手机及它们内置的 A11 Bionic 芯片。A11 Bionic 中自主研发的双核架构 Neural Engine(神经网络处理引擎),它每秒处理相应神经网络计算需求的次数可达 6000 亿次。这个 Neural Engine 的出现,让 A11 Bionic 成为一块真正的 AI 芯片。 A11 Bionic 大大提升了 iPhone X 在拍照方面的使用体验,并提供了一些富有创意的新用法。
(2)ADAS(高级辅助驾驶系统)
ADAS 是最吸引大众眼球的人工智能应用之一, 它需要处理海量的由激光雷达、毫米波雷达、摄像头等传感器采集的实时数据。相对于传统的车辆控制方法,智能控制方法主要体现在对控制对象模型的运用和综合信息学习运用上,包括神经网络控制和深度学习方法等,得益于 AI 芯片的飞速发展, 这些算法已逐步在车辆控制中得到应用。
(3)CV(计算机视觉(Computer Vision) 设备
需要使用计算机视觉技术的设备,如智能摄像头、无人机、 行车记录仪、人脸识别迎宾机器人以及智能手写板等设备, 往往都具有本地端推断的需要,如果仅能在联网下工作,无疑将带来糟糕的体验。而计算机视觉技术目前看来将会成为人工智能应用的沃土之一,计算机视觉芯片将拥有广阔的市场前景。
(4) VR 设备
VR 设备芯片的代表为 HPU 芯片, 是微软为自身 VR 设备 Hololens 研发定制的。 这颗由台积电代工的芯片能同时处理来自 5个摄像头、 1个深度传感器以及运动传感器的数据,并具备计算机视觉的矩阵运算和 CNN 运算的加速功能。这使得 VR 设备可重建高质量的人像 3D 影像,并实时传送到任何地方。
(5)语音交互设备
语音交互设备芯片方面,国内有启英泰伦以及云知声两家公司,其提供的芯片方案均内置了为语音识别而优化的深度神经网络加速方案,实现设备的语音离线识别。稳定的识别能力为语音技术的落地提供了可能; 与此同时,语音交互的核心环节也取得重大突破。语音识别环节突破了单点能力,从远场识别,到语音分析和语义理解有了重大突破,呈现出一种整体的交互方案。
(6)机器人
无论是家居机器人还是商用服务机器人均需要专用软件+芯片的人工智能解决方案,这方面典型公司有由前百度深度学习实验室负责人余凯创办的地平线机器人,当然地平线机器人除此之外,还提供 ADAS、智能家居等其他嵌入式人工智能解决方案。
2、AI芯片国内外代表性企业
本篇将介绍目前人工智能芯片技术领域的国内外代表性企业。文中排名不分先后。人工智能芯片技术领域的国内代表性企业包括中科寒武纪、中星微、地平线机器人、深鉴科技、 灵汐科技、 启英泰伦、百度、华为等,国外包括英伟达、 AMD、 Google、高通、Nervana Systems、 Movidius、 IBM、 ARM、 CEVA、 MIT/Eyeriss、苹果、三星等。
中科寒武纪。寒武纪科技成立于 2016 年,总部在北京,创始人是中科院计算所的陈天石、陈云霁兄弟,公司致力于打造各类智能云服务器、智能终端以及智能机器人的核心处理器芯片。阿里巴巴创投、联想创投、国科投资、中科图灵、元禾原点、涌铧投资联合投资,为全球 AI芯片领域第一个独角兽初创公司。
寒武纪是全球第一个成功流片并拥有成熟产品的 AI 芯片公司,拥有终端 AI 处理器 IP和云端高性能 AI 芯片两条产品线。 2016 年发布的寒武纪 1A 处理器(Cambricon-1A) 是世界首款商用深度学习专用处理器,面向智能手机、安防监控、无人机、可穿戴设备以及智能驾驶等各类终端设备,在运行主流智能算法时性能功耗比全面超越传统处理器。
中星微。1999 年, 由多位来自硅谷的博士企业家在北京中关村科技园区创建了中星微电子有限公司, 启动并承担了国家战略项目――“星光中国芯工程”,致力于数字多媒体芯片的开发、设计和产业化。
2016 年初,中星微推出了全球首款集成了神经网络处理器(NPU)的 SVAC 视频编解码 SoC,使得智能分析结果可以与视频数据同时编码,形成结构化的视频码流。该技术被广泛应用于视频监控摄像头,开启了安防监控智能化的新时代。自主设计的嵌入式神经网络处理器(NPU)采用了“数据驱动并行计算” 架构,专门针对深度学习算法进行了优化,具备高性能、低功耗、高集成度、小尺寸等特点,特别适合物联网前端智能的需求。

▲集成了 NPU 的神经网络处理器 VC0616 的内部结构
地平线机器人(Horizon Robotics)。地平线机器人成立于 2015 年,总部在北京,创始人是前百度深度学习研究院负责人余凯。BPU(BrainProcessing Unit) 是地平线机器人自主设计研发的高效人工智能处理器架构IP,支持 ARM/GPU/FPGA/ASIC 实现,专注于自动驾驶、人脸图像辨识等专用领域。 2017年,地平线发布基于高斯架构的嵌入式人工智能解决方案,将在智能驾驶、智能生活、公共安防三个领域进行应用,第一代 BPU芯片“盘古” 目前已进入流片阶段,预计在 2018年下半年推出,能支持 1080P 的高清图像输入,每秒钟处理 30 帧,检测跟踪数百个目标。地平线的第一代 BPU 采用 TSMC 的 40nm工艺,相对于传统 CPU/GPU, 能效可以提升 2~3 个数量级(100~1,000 倍左右)。
深鉴科技。深鉴科技成立于 2016 年,总部在北京。由清华大学与斯坦福大学的世界顶尖深度学习硬件研究者创立。深鉴科技于 2018 年 7 月被赛灵思收购。深鉴科技将其开发的基于 FPGA 的神经网络处理器称为 DPU。到目前为止,深鉴公开发布了两款 DPU:亚里士多德架构和笛卡尔架构,其中,亚里士多德架构是针对卷积神经网络 CNN 而设计;笛卡尔架构专为处理 DNN/RNN 网络而设计,可对经过结构压缩后的稀疏神经网络进行极致高效的硬件加速。相对于 Intel XeonCPU 与 Nvidia TitanX GPU,应用笛卡尔架构的处理器在计算速度上分别提高 189 倍与 13 倍,具有 24,000 倍与 3,000 倍的更高能效。
灵汐科技。灵汐科技于 2018 年 1 月在北京成立,联合创始人包括清华大学的世界顶尖类脑计算研究者。公司致力于新一代神经网络处理器(Tianjic) 开发, 特点在于既能够高效支撑现有流行的机器学习算法(包括 CNN, MLP, LSTM 等网络架构),也能够支撑更仿脑的、更具成长潜力的脉冲神经网络算法; 使芯片具有高计算力、高多任务并行度和较低功耗等优点。 软件工具链方面支持由 Caffe、 TensorFlow 等算法平台直接进行神经网络的映射编译,开发友善的用户交互界面。 Tianjic 可用于云端计算和终端应用场景,助力人工智能的落地和推广。
启英泰伦。启英泰伦于2015年 11月在成都成立,是一家语音识别芯片研发商。启英泰伦的 CI1006是基于 ASIC 架构的人工智能语音识别芯片,包含了脑神经网络处理硬件单元,能够完美支持 DNN 运算架构,进行高性能的数据并行计算,可极大的提高人工智能深度学习语音技术对大量数据的处理效率。
百度。百度 2017 年 8 月 Hot Chips 大会上发布了 XPU,这是一款 256 核、基于 FPGA 的云计算加速芯片。合作伙伴是赛思灵(Xilinx)。 XPU 采用新一代 AI 处理架构,拥有 GPU 的通用性和 FPGA 的高效率和低能耗,对百度的深度学习平台 PaddlePaddle 做了高度的优化和加速。据介绍, XPU 关注计算密集型、基于规则的多样化计算任务,希望提高效率和性能,并带来类似 CPU 的灵活性。
华为。麒麟 970 搭载的神经网络处理器 NPU 采用了寒武纪 IP,如图 12 所示。麒麟 970 采用了 TSMC 10nm 工艺制程,拥有 55 亿个晶体管,功耗相比上一代芯片降低 20%。 CPU 架构方面为 4 核 A73+4 核 A53 组成 8 核心,能耗同比上一代芯片得到 20%的提升; GPU 方面采用了 12 核 Mali G72 MP12GPU,在图形处理以及能效两项关键指标方面分别提升 20%和50%; NPU 采用 HiAI移动计算架构,在 FP16 下提供的运算性能可以达到 1.92 TFLOPs,相比四个 Cortex-A73 核心,处理同样的 AI 任务,有大约具备 50 倍能效和 25 倍性能优势。
英伟达(Nvidia)。英伟达创立于 1993 年,总部位于美国加利福尼亚州圣克拉拉市。 早在 1999 年, 英伟达发明了 GPU,重新定义了现代计算机图形技术,彻底改变了并行计算。深度学习对计算速度有非常苛刻的要求, 而英伟达的 GPU 芯片可以让大量处理器并行运算,速度比 CPU 快十倍甚至几十倍,因而成为绝大部分人工智能研究者和开发者的首选。自从 Google Brain 采用 1.6 万个 GPU 核训练 DNN 模型, 并在语音和图像识别等领域获得巨大成功以来, 英伟达已成为 AI 芯片市场中无可争议的领导者。
AMD。美国 AMD 半导体公司专门为计算机、 通信和消费电子行业设计和制造各种创新的微处理器(CPU、 GPU、 APU、 主板芯片组、 电视卡芯片等),以及提供闪存和低功率处理器解决方案, 公司成立于 1969 年。 AMD 致力为技术用户――从企业、 政府机构到个人消费者――提供基于标准的、 以客户为中心的解决方案。
2017 年 12 月 Intel 和 AMD 宣布将联手推出一款结合英特尔处理器和 AMD 图形单元的笔记本电脑芯片。 目前 AMD 拥有针对 AI 和机器学习的高性能 Radeon Instinc 加速卡,开放式软件平台 ROCm 等。
Google 。Google 在 2016 年宣布独立开发一种名为 TPU 的全新的处理系统。 TPU 是专门为机器学习应用而设计的专用芯片。通过降低芯片的计算精度,减少实现每个计算操作所需晶体管数量的方式,让芯片的每秒运行的操作个数更高,这样经过精细调优的机器学习模型就能在芯片上运行得更快,进而更快地让用户得到更智能的结果。 在 2016 年 3 月打败了李世石和 2017 年 5 月打败了柯杰的阿尔法狗,就是采用了谷歌的 TPU 系列芯片。
Google I/O-2018 开发者大会期间,正式发布了第三代人工智能学习专用处理器 TPU 3.0。TPU3.0 采用 8 位低精度计算以节省晶体管数量, 对精度影响很小但可以大幅节约功耗、加快速度,同时还有脉动阵列设计,优化矩阵乘法与卷积运算, 并使用更大的片上内存,减少对系统内存的依赖。 速度能加快到最高 100PFlops(每秒 1000 万亿次浮点计算)。
高通。在智能手机芯片市场占据绝对优势的高通公司,也在人工智能芯片方面积极布局。据高通提供的资料显示,其在人工智能方面已投资了 Clarifai 公司和中国“专注于物联网人工智能服务” 的云知声。而早在 2015 年 CES 上,高通就已推出了一款搭载骁龙 SoC 的飞行机器人――Snapdragon Cargo。高通认为在工业、农业的监测以及航拍对拍照、摄像以及视频新需求上,公司恰好可以发挥其在计算机视觉领域的能力。此外,高通的骁龙 820 芯片也被应用于 VR头盔中。事实上,高通已经在研发可以在本地完成深度学习的移动端设备芯片。
Nervana Systems。Nervana 创立于 2014 年, 公司推出的 The Nervana Engine 是一个为深度学习专门定制和优化的 ASIC 芯片。这个方案的实现得益于一项叫做 High Bandwidth Memory 的新型内存技术, 这项技术同时拥有高容量和高速度,提供 32GB 的片上储存和 8TB 每秒的内存访问速度。该公司目前提供一个人工智能服务“in the cloud” ,他们声称这是世界上最快的且目前已被金融服务机构、医疗保健提供者和政府机构所使用的服务。 他们的新型芯片将会保证 Nervana 云平台在未来的几年内仍保持最快的速度。
Movidius(被 Intel 收购)。2016 年 9 月, Intel 发表声明收购了 Movidius。 Movidius 专注于研发高性能视觉处理芯片。其最新一代的 Myriad2 视觉处理器主要由 SPARC 处理器作为主控制器,加上专门的DSP 处理器和硬件加速电路来处理专门的视觉和图像信号。这是一款以 DSP 架构为基础的视觉处理器,在视觉相关的应用领域有极高的能耗比,可以将视觉计算普及到几乎所有的嵌入式系统中。
该芯片已被大量应用在 Google 3D 项目的 Tango 手机、大疆无人机、 FLIR 智能红外摄像机、海康深眸系列摄像机、华睿智能工业相机等产品中。
IBM。IBM 很早以前就发布过 watson,投入了很多的实际应用。除此之外,还启动了类脑芯片的研发, 即 TrueNorth。TrueNorth 是 IBM 参与 DARPA 的研究项目 SyNapse 的最新成果。 SyNapse 全称是Systems of Neuromorphic Adaptive Plastic Scalable Electronics(自适应可塑可伸缩电子神经系统,而 SyNapse 正好是突触的意思),其终极目标是开发出打破冯・诺依曼体系结构的计算机体系结构。
ARM。ARM 推出全新芯片架构 DynamIQ,通过这项技术, AI 芯片的性能有望在未来三到五年内提升 50 倍。
ARM的新CPU架构将会通过为不同部分配置软件的方式将多个处理核心集聚在一起,这其中包括一个专门为 AI 算法设计的处理器。芯片厂商将可以为新处理器配置最多 8 个核心。同时为了能让主流 AI 在自己的处理器上更好地运行, ARM 还将推出一系列软件库。
CEVA。CEVA 是专注于 DSP 的 IP 供应商,拥有众多的产品线。其中,图像和计算机视觉 DSP产品 CEVA-XM4是第一个支持深度学习的可编程 DSP,而其发布的新一代型号 CEVA-XM6,具有更优的性能、更强大的计算能力以及更低的能耗。CEVA 指出,智能手机、汽车、安全和商业应用,如无人机、自动化将是其业务开展的主要目标。
MIT/Eyeriss。Eyeriss 事实上是 MIT 的一个项目,还不是一个公司, 从长远来看,如果进展顺利,很可能孵化出一个新的公司。Eyeriss 是一个高效能的深度卷积神经网络(CNN)加速器硬件,该芯片内建 168 个核心,专门用来部署神经网路(neural network),效能为一般 GPU 的 10 倍。其技术关键在于最小化 GPU 核心和记忆体之间交换数据的频率(此运作过程通常会消耗大量的时间与能量):一般 GPU 内的核心通常共享单一记忆体,但 Eyeriss 的每个核心拥有属于自己的记忆体。
目前, Eyeriss 主要定位在人脸识别和语音识别,可应用在智能手机、穿戴式设备、机器人、自动驾驶车与其他物联网应用装置上。
苹果。在 iPhone 8 和 iPhone X 的发布会上,苹果明确表示其中所使用的 A11 处理器集成了一个专用于机器学习的硬件――“神经网络引擎(Neural Engine) ”, 每秒运算次数最高可达6000 亿次。这块芯片将能够改进苹果设备在处理需要人工智能的任务时的表现,比如面部识别和语音识别等。
三星。2017 年,华为海思推出了麒麟 970 芯片,据知情人士透露,为了对标华为,三星已经研发了许多种类的人工智能芯片。 三星计划在未来三年内新上市的智能手机中都采用人工智能芯片,并且他们还将为人工智能设备建立新的组件业务。三星还投资了Graphcore、深鉴科技等人工智能芯片企业。
3、技术趋势
目前主流 AI 芯片的核心主要是利用 MAC(Multiplier and Accumulation, 乘加计算) 加速阵列来实现对 CNN(卷积神经网络)中最主要的卷积运算的加速。这一代 AI 芯片主要有如下 3 个方面的问题。
(1)深度学习计算所需数据量巨大,造成内存带宽成为整个系统的瓶颈,即所谓“memory wall” 问题。
(2)与第一个问题相关, 内存大量访问和 MAC阵列的大量运算,造成 AI芯片整体功耗的增加。
(3)深度学习对算力要求很高,要提升算力,最好的方法是做硬件加速,但是同时深度学习算法的发展也是日新月异,新的算法可能在已经固化的硬件加速器上无法得到很好的支持,即性能和灵活度之间的平衡问题。
因此可以预见下一代 AI 芯片将有如下的五个发展趋势。
(1)、更高效的大卷积解构/复用
在标准 SIMD 的基础上, CNN 由于其特殊的复用机制,可以进一步减少总线上的数据通信。而复用这一概念,在超大型神经网络中就显得格外重要。 如何合理地分解、 映射这些超大卷积到有效的硬件上成为了一个值得研究的方向,
(2)、更低的 Inference 计算/存储位宽
AI 芯片最大的演进方向之一可能就是神经网络参数/计算位宽的迅速减少――从 32 位浮点到 16 位浮点/定点、 8 位定点,甚至是 4 位定点。在理论计算领域, 2 位甚至 1 位参数位宽,都已经逐渐进入实践领域。
(3)、更多样的存储器定制设计
当计算部件不再成为神经网络加速器的设计瓶颈时,如何减少存储器的访问延时将会成为下一个研究方向。通常,离计算越近的存储器速度越快,每字节的成本也越高,同时容量也越受限,因此新型的存储结构也将应运而生。
(4)、更稀疏的大规模向量实现
神经网络虽然大,但是,实际上有很多以零为输入的情况, 此时稀疏计算可以高效的减少无用能效。来自哈佛大学的团队就该问题提出了优化的五级流水线结,在最后一级输出了触发信号。在 Activation层后对下一次计算的必要性进行预先判断,如果发现这是一个稀疏节点,则触发 SKIP 信号,避免乘法运算的功耗,以达到减少无用功耗的目的。
(5)、计算和存储一体化
计算和存储一体化(process-in-memory)技术,其要点是通过使用新型非易失性存储(如 ReRAM)器件,在存储阵列里面加上神经网络计算功能,从而省去数据搬移操作,即实现了计算存储一体化的神经网络处理,在功耗性能方面可以获得显著提升。
近几年,AI技术不断取得突破性进展。作为AI技术的重要物理基础,AI芯片拥有巨大的产业价值和战略地位。但从大趋势来看,目前尚处于AI芯片发展的初级阶段,无论是科研还是产业应用都有巨大的创新空间。现在不仅英伟达、谷歌等国际巨头相继推出新产品,国内百度、阿里等纷纷布局这一领域,也诞生了寒武纪等AI芯片创业公司。在CPU、GPU等传统芯片领域与国际相差较多的情况下,中国AI芯片被寄望能实现弯道超车。