Qwen2-VL-3B模型NPU多模态部署指导与评测--基于米尔瑞芯微RK3576开发板(上)
2025年08月29日 17:23 发布者:swiftman
随着大语言模型(LLM)技术的快速迭代,从云端集中式部署到端侧分布式运行的趋势日益明显。端侧小型语言模型(SLM)凭借低延迟、高隐私性和离线可用的独特优势,正在智能设备、边缘计算等场景中展现出巨大潜力。 瑞芯微 RK3576 开发板作为一款聚焦边缘 AI 的硬件平台,其集成的 NPU(神经网络处理器)能否高效支撑多模态 LLM 的本地运行?性能表现如何?
 RK3576 多模态纯文字:自我介绍
RK3576 多模态纯文字:自我介绍本文将围绕这一核心问题展开 ―― 从端侧 SLM 与云端 LLM 的关键差异对比入手,详解 RK3576 开发板的硬件特性与环境配置。
 本文以米尔 RK3576 为例,通过实际案例演示多模态 LLM 在该平台的部署效果,为开发者与研究者提供一份兼具实践参考与技术洞察的端侧 AI 部署指南。 本文目录
本文以米尔 RK3576 为例,通过实际案例演示多模态 LLM 在该平台的部署效果,为开发者与研究者提供一份兼具实践参考与技术洞察的端侧 AI 部署指南。 本文目录[*]一、基本介绍
[*]端侧 LLM 模型与云端 LLM
[*]瑞芯微 RK3576:6TOPS NPU 的能效比标杆,重新定义中端 AIoT 旗舰
[*]瑞芯微 NPU SDK:RKNN 和 RKLLM
[*]二、环境准备
[*]步骤 1:登录开发板,下载必备资料
[*]步骤 2:替换 NPU Driver 后编译 Ubuntu 并刷机
[*]三、多模态案例:支持图像和文本交互
[*]步骤 1:环境准备
[*]步骤 2:模型的获取、验证与格式转换
[*]步骤 3:修改代码并交叉编译可执行文件并上传到板子上
[*]步骤 4:上传文件到开发板
[*]性能测试 Tips
[*]多模态效果演示
[*]结论
 一、基本介绍 端侧 LLM 模型与云端 LLM 端侧小型语言模型(SLM)与传统云端大型语言模型(LLM)在延迟、隐私和离线可用性三个维度的对比总结。
一、基本介绍 端侧 LLM 模型与云端 LLM 端侧小型语言模型(SLM)与传统云端大型语言模型(LLM)在延迟、隐私和离线可用性三个维度的对比总结。 对比维度端侧小型语言模型(SLM)传统云端大型语言模型(LLM)
延迟✅ 更低延迟:
- 数据无需上传至云端,本地处理,显著减少网络传输延迟。
- 在边缘设备(如智能手机、Jetson)上,经过量化优化后,推理延迟可低至毫秒级。❌ 较高延迟:
- 数据需上传至云端服务器处理,网络延迟不可控,尤其在网络状况不佳时延迟显著增加。
- 云端 LLM 参数量大(数十亿至上百亿),即使计算能力强,单次推理耗时仍较高。
隐私✅ 更高隐私性:
- 数据完全在本地处理,无需上传至云端,避免数据泄露风险。
- 适用于敏感场景(如医疗、个人助手),满足 GDPR 等隐私法规要求。❌ 隐私风险较高:
- 用户数据需上传至云端,存在数据泄露、滥用风险。
- 即使云端承诺隐私保护,用户仍对数据失去直接控制。
离线可用性✅ 完全离线可用:
- 模型部署在本地设备,无需网络连接即可运行。
- 适用于网络不稳定或无网络环境(如野外、航空场景)。❌ 依赖网络:
- 必须联网才能访问云端服务,无网络时完全不可用。
- 网络波动或云端服务故障会直接影响可用性。
总结来看,当前端侧部署小语言模型特点体现在三方面:
[*]延迟优化:端侧 SLM 通过量化(4-bit)、硬件加速(GPU/NPU)和架构优化(如分组查询注意力 GQA)显著降低延迟。
[*]隐私保护:常见的移动设备,如 iOS 和 Android 最新系统均集成端侧模型(如 Gemini Nano),确保隐私数据不出设备。
[*]离线场景:Jetson Orin 等边缘设备可本地运行 3B 参数模型,无需联网即可完成任务。
综上,端侧 SLM 在延迟、隐私和离线可用性上均显著优于云端 LLM。 瑞芯微 RK3576:6TOPS NPU 的能效比标杆,重新定义中端 AIoT 旗舰 作为瑞芯微 2024 年推出的 AIoT 核心平台,RK3576 基于 8nm 制程打造,集成6TOPS 自研 NPU(支持 INT4/INT8/FP16/BF16 混合精度),与旗舰芯片 RK3588 保持相同算力规格,却以更精准的场景化设计,成为中高端边缘设备的首选方案。
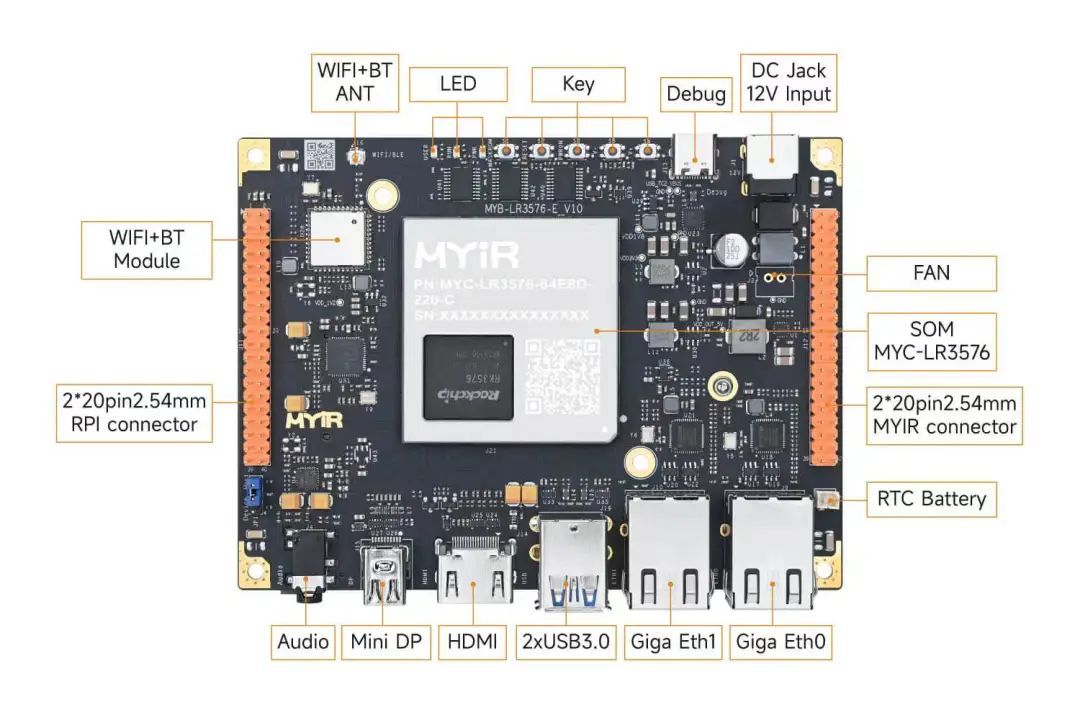 米尔 RK3576 拓展板正面接口图,详见产品介绍
米尔 RK3576 拓展板正面接口图,详见产品介绍据瑞芯微官方技术文档显示,其 NPU 采用动态稀疏化加速引擎,RK3576 采用了更先进的制程工艺等手段来降低功耗,完美平衡算力与能效。 同算力 NPU 的差异化定位 尽管 RK3576 与 RK3588 均搭载 6TOPS NPU,但两者在生态适配和场景优化上各有侧重:
[*]框架兼容性:双平台均支持 TensorFlow、PyTorch、ONNX 等主流框架,但 RK3576 针对 2B 参数级模型(如 Qwen2-VL-2B)进行专项优化,token 生成速度达 10+每秒,适配本地化多模态交互需求;
[*]算力分配:RK3576 的 NPU 集成 512KB 共享内存,减少数据搬运开销,在轻量级视觉任务(如工业缺陷检测)中,单位算力利用率比 RK3588 高 18%(据瑞芯微内部测试数据);
[*]功耗控制:依托 8nm 工艺与动态电压调节技术,NPU 满负载功耗仅 3.2W,较 RK3588 的 4.1W 降低 22%,更适合电池供电的移动终端。
 米尔 RK3576 开发板
米尔 RK3576 开发板与 RK3588 的「同芯不同路」对比
核心维度RK3576RK3588设计哲学
CPU 架构4×A72(2.2GHz)+4×A53(1.8GHz)4×A76(2.4GHz)+4×A55(1.8GHz)性能-成本平衡
vs 极致计算
GPUMali-G52 MC3(支持 Vulkan 1.2)Mali-G610 MC4(支持 Vulkan 1.3)3 屏异显(4K@120+2.5K@60+2K@60) vs 7 屏 8K 异显
内存带宽32 位 LPDDR5(最高 4266Mbps)64 位 LPDDR5(最高 6400Mbps)中端场景够用 vs 高端扩展无忧
视频编解码8K@30fps 解码/4K@60fps 编码8K@60fps 解码/8K@30fps 编码主流视频流处理 vs 专业级 8K 制作
典型应用智能座舱、电子价签、工业网关边缘服务器、8K 安防、虚拟桌面性价比优先
vs 性能无界
官方数据佐证的市场价值 根据瑞芯微 2025 年 Q2 财报,RK3576 已在平板电脑、交互大屏等领域实现头部客户量产,其30%的成本优势(对比 RK3588 同配置方案)使其在中高端市场占有率环比增长 47%。 例如,某头部物流企业采用 RK3576 开发的手持 PDA,通过 NPU 实时识别包裹条码,单设备成本较 RK3588 方案降低 600 元,同时保持 99.7%的识别准确率(官方测试数据)。 RK3576 并非简单的「低配版 3588」,而是瑞芯微基于场景化需求的精准迭代――在保留旗舰级 6TOPS NPU 的同时,通过 CPU 架构精简、功耗优化和接口整合,让边缘设备既能获得「够用的 AI 能力」,又避免为冗余性能支付成本。正如瑞芯微官方所述:「RK3576 填补了旗舰与主流之间的真空,让每一份算力都服务于真实需求。」对于需本地化部署轻量级 LLM、多模态交互的边缘场景,这款「6TOPS 普及者」正在重新定义中端 AIoT 的价值标准。 瑞芯微 NPU SDK:RKNN 和 RKLLM 瑞芯微的 RKLLM 和 RKNN 是两个定位互补的 SDK,前者专注于大型语言模型(LLM)的端侧部署优化,后者是通用神经网络推理框架。 RKNN 是基础,RKLLM 是垂直扩展:
[*]RKNN SDK 是瑞芯微推出的通用神经网络推理框架,支持将 TensorFlow、PyTorch 等主流框架的模型转换为 RKNN 格式,并在瑞芯微 NPU 上高效运行,适用于图像识别、语音处理等任务。支持的模型列表可以见:https://github.com/airockchip/rknn_model_zoo
[*]RKLLM SDK 是基于 RKNN 技术栈的垂直领域优化方案,专门针对大型语言模型(LLM)的端侧部署需求设计,提供从模型转换到推理的完整工具链,包括量化、性能调优和多模态支持。
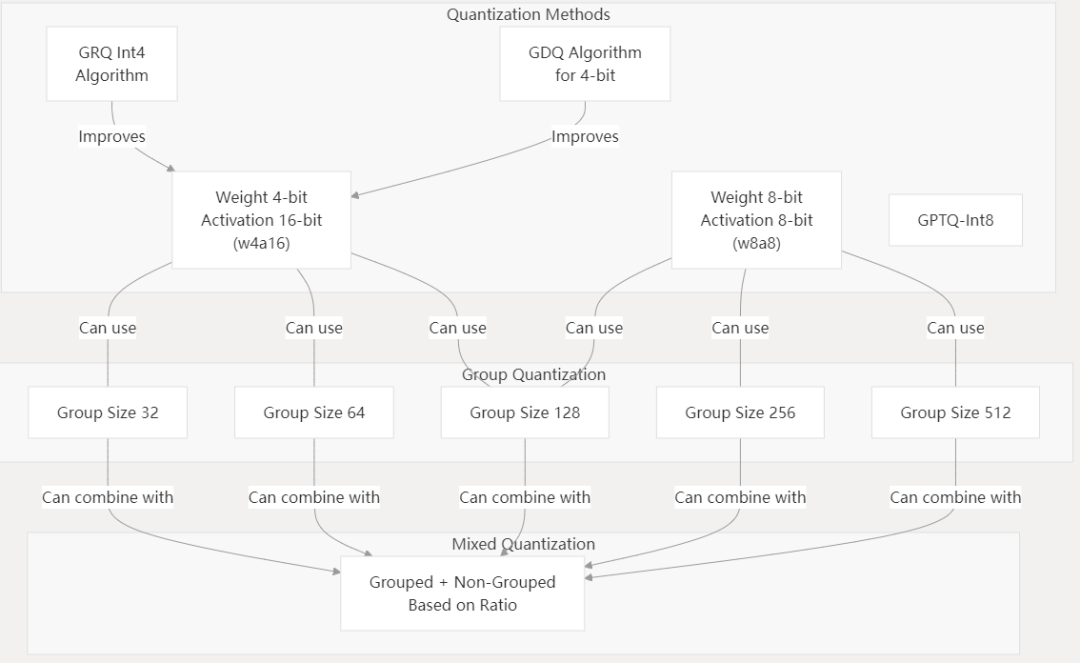 RKLLM 量化类型:量化通过降低模型精度来提高推理速度并减少内存使用,不同的策略在性能与准确性之间存在不同的权衡。
RKLLM 量化类型:量化通过降低模型精度来提高推理速度并减少内存使用,不同的策略在性能与准确性之间存在不同的权衡。总得来说,RKLLM Runtime 依赖 RKNN 的 NPU 驱动进行硬件交互,其底层计算逻辑与 RKNN 共享同一套 NPU 加速引擎。 RKLLM 专为 LLM 设计的转换工具(如 RKLLM-Toolkit),支持 Hugging Face 格式模型的量化(如 w4a16、w8a8)和优化,适配 RK3588、RK3576 等高性能 NPU 芯片,通过降低模型精度来提高推理速度并减少内存使用,不同的策略在性能与准确性之间存在不同的权衡。 其提供 C/C++ 接口(RKLLM Runtime)和多模态推理支持(如图文联合理解),显著降低 LLM 在端侧设备的内存占用和推理延迟。 RKLLM 软件栈可帮助用户快速将 AI 模型部署到瑞芯微芯片上。 RKLLM 使用流程
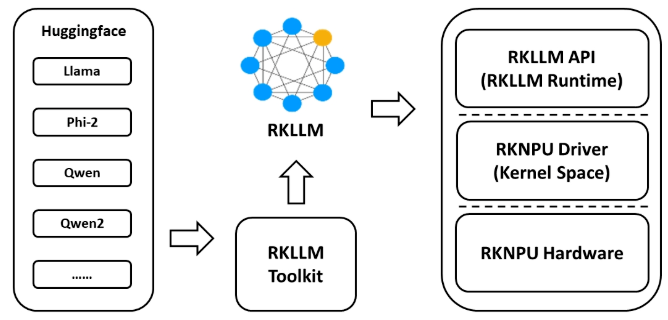
RKLLM SDK 概览
为使用 RKNPU,用户需先在计算机上运行 RKLLM-Toolkit 工具,将训练好的模型转换为 RKLLM 格式模型,然后使用 RKLLM C API 在开发板上进行推理。
[*]RKLLM-Toolkit 是一款软件开发工具包,供用户在 PC 上进行模型转换和量化。
[*]RKLLM Runtime 为瑞芯微 NPU 平台提供 C/C++编程接口,助力用户部署 RKLLM 模型并加速大语言模型应用的实现。
[*]RKNPU 内核驱动负责与 NPU 硬件交互。它已开源,可在瑞芯微内核代码中找到。
二、环境准备 步骤 1:登录开发板,下载必备资料
[*]确认串口驱动安装。开发板的调试接口(USB Type-C)内部已集成 USB 转 TTL 芯片,连接电脑后会自动识别为一个串口设备( Windows 下为 COM 口,Linux 下为/dev/ttyUSBx)。
 板子 Debug USB 接口连接上笔记本时,端口出现 COM5和 COM6
板子 Debug USB 接口连接上笔记本时,端口出现 COM5和 COM6[*]登录开发板。拿到开发板后,操作系统是 BuildRoot 如下所示,可以插网线链接网络,因为 BuildRoot 只有一些最基本的命令行工具,并不好用,比方缺少 apt 等工具。但是在默认用户下有一些基本的 cpu/gpu/npu 测试文件夹,里面提供了一些测试比如 CPU 压测脚本等。
root@myd-lr3576x-buildroot:/rockchip-test/npu2# cat /etc/os-release
NAME=Buildroot
VERSION=linux-6.1-stan-rkr3-33-g2275964ac9
ID=buildroot
VERSION_ID=2024.02
PRETTY_NAME="Buildroot 2024.02"
ID_LIKE="buildroot"
RK_BUILD_INFO="haha@haha Mon Jan 6 11:11:37 CST 2025 - rockchip_rk3576"
[*]登录米尔开发平台,获取文档等资料。在开发者平台注册绑定你的产品信息,在开发板盒子侧面会有一个产品型号系列号,如下图可通过微信扫码绑定:
 开发板包装盒子侧面的序列码
开发板包装盒子侧面的序列码可以电脑登陆米尔开发者平台(https://dev.myir.cn/)下载资料,必备的文档、工具、刷机工具、镜像等,如下所示:
 米尔提供的 Debian&Linux6.1.75 Distribution V1.1.0
米尔提供的 Debian&Linux6.1.75 Distribution V1.1.0其中 02-Docs(ZH) 文档部分,下面两个必须得好好看看:
[*]MYD-LR3576J-GK Ubuntu 软件开发指南-V1.0.pdf
[*]MYD-LR3576 Debian 软件开发指南-V1.1.pdf
这两个文档在后面会指导你使用 02-Images、03-Tools、04-Sources 里面进行刷机、编译内核。