为大模型定制一颗芯片?
2024年04月06日 11:36 发布者:eechina
来源:半导体行业观察当我们回顾2023年爆火的AI时,有两位明星获得了最多的关注度,一位是开发了ChatGPT的OpenAI,另一位是为各路AI选手提供雄厚算力的英伟达。
逢大模型必提OpenAI,逢显卡必提英伟达,成了过往一年的常态。
但这样的情形必然不会持续太久,不论是AI大模型还是AI显卡,都是动辄每年上百亿美元乃至于千亿美元的市场,大家都不想让两家厂商独吞蛋糕。
在大模型上,LaMDA 、LLaMA、Gemini等早已虎视眈眈,而在显卡上,不光有传统的英特尔与AMD这两家,还有各类定制与自研芯片涌现,OpenAI与英伟达已经迎来了各自的竞争对手。
但更有意思的事情也在发生,AI的软件和硬件并非天然对立,如果把大型语言模型和显卡芯片结合在一起,会有什么样的奇妙反应呢?
为大模型量身打造芯片
想要训练一个大模型,代表算力的芯片就是最关键的一环,也是成本最高的一环。
这也导致了一个问题,如果AI照着现在这幅样子发展下去,那么成本就会越来越高,高到绝大部分公司都难以承受的地步,根据外媒估计,如今正在开发的大模型,平均每个需要花费约 10 亿美元,而下一代大模型呢,平均每个需要花费 100 亿美元来训练,这个天文数字,在硅谷买下几十家有潜力的初创公司都还有得找。
这也暴露出了目前行业最常用的英伟达显卡的弊端,英伟达的GPU并非为了AI而生,它起初是为了处理各种各样的图形化计算而生产制造的,整体设计也没有脱离传统计算的范畴,面对人工智能蓬勃发展时,强大的算力有相当一部分被浪费了,也意味着白花花的银子被浪费了。
大公司可以一边着手自研,一边继续购买英伟达的显卡,但对于中小型公司来说,显卡成为了他们最大的绊脚石,如此一来,AI在某种程度上就成为了一部分公司的专属。
不过这种需求已被一部分人所注意到,在美国硅谷,迈克-冈特(Mike Gunter)和雷纳-波普(Reiner Pope)这两位从谷歌出走的工程师,他们成立了一家名为 MatX 的公司,而这家公司的目标,就是设计专门用于LLM(大型语言模型)的,更便宜、更快速、更适合人工智能的芯片。
在谷歌任职时,Gunter主要负责设计运行人工智能软件的硬件(包括芯片),Pope则负责编写人工智能软件本身,这里不得不提到谷歌此前自研的TPU了,从2014年发展至今,已经更迭了整整五代,但它们和英伟达H100一样,都不是为了LLM所量身打造的,放在人工智能领域中,显得过于通用了一些。
Pope在接受采访时表示:“我们试图让LLM在谷歌运行得更快,并取得了一些进展,但这有点困难,”他说到,“在谷歌内部,有很多人希望对芯片进行各种改动,因此很难只专注于 LLM。为此,我们选择了离开。”
这两位创始人都认为,在人工智能时代到来之际,芯片上额外的空间增加了不必要的成本和复杂性,因此需要“一刀切”,去掉所有不必要的部分,只保留必要的部分,MatX公司的做法就是在硅片上设计一个大型处理内核,目的只有一个,那就是尽可能快地将数字相乘――这是 LLM 的核心任务。
MatX表示,自己的芯片在训练 LLM 和提供其结果方面将比英伟达的 GPU 至少好 10 倍。“英伟达有非常强大的产品,显然是大多数公司的理想选择,” Pope说,“但我们认为我们可以做得更好。
其预测,通过赢得包括OpenAI和Anthropic PBC在内的多家主要人工智能企业的青睐,它的业务将蒸蒸日上。“这些公司的经济状况与一般公司完全相反,"Gunter说,"他们把钱都花在了计算上,而不是工资上。如果情况不改变,他们就会没钱。”
无独有偶,隔壁总部位于多伦多的人工智能芯片初创公司 Taalas,同样立志于改变由英伟达主导的AI世界,公司创始人包括Ljubisa Bajic、Lejla Bajic 和 Drago Ignjatovic,他们均来自传奇架构师Jim Keller所领导的Tenstorrent。
与前东家Tenstorrent不同的是,Taalas几位创始人想开发一种自动流程,能将任何人工智能模型快速转化为定制芯片,其表示,由此产生的硬核模型的效率是软件模型的 1000 倍。
“要实现人工智能的商品化,就必须将计算能力和效率提高 1000 倍,而目前的渐进式方法是无法实现这一目标的。我们不应该在通用计算机上模拟智能,而应该直接在芯片中打造智能,在芯片中实现深度学习模型是实现可持续人工智能的最直接途径。”Taalas 首席执行官Ljubisa Bajic说。
Taalas认为,公司会解决了当今人工智能硬件的两大问题,即能效和成本。如果客户需要在手机里使用特定参数Llama2模型,而且确定了产品生命周期中的全部需求,那么可能只需要为它提供一款最低功耗和最低成本的专用芯片,未来的AI在消费者日常生活中的普及程度将像电力一样无处不在,而Taalas认为自己能够推动这一切的发展。
Taalas表示,它将在2024年第三季度推出首款大型语言模型芯片,并计划在2025年第一季度向首批客户提供芯片。
目前,这两家打算颠覆目前AI芯片市场的公司都拿到了一笔数额不菲的投资,MatX获得了2500万美元的融资,而Taalas则获得了5000万美元的融资。
MatX的投资人提到,MatX这样的公司象征着人工智能世界的一种新趋势,因为他们正在把一些大公司开发出来的最好的创意(这些公司有点行动太慢、太官僚化)独立商业化,硅谷之所以能成为硅谷,正是因为一批又批充满活力的初创公司,初创公司能改变目前芯片行业沉闷的情况。
但问题也随之而来,设计芯片并不是吃饭喝水那么简单,设计和制造一款新芯片需要三到五年的时间,中间还不能出现重大失误,五年前的想法拿到现在来看,不少已然过时,这就要求这些初创公司对未来技术趋势有一个更准确的判断。
上个月,英伟达已经推出了全新的B200芯片,原本可能上百倍的差距,或许已经缩小到数十倍,随着时间的推移,这部分差距只会越来越小,到了优势不那么明显的时候,恐怕这些初创公司就很难说服英伟达原来的客户迁移到新芯片之上了。
消费端客户关心体验和效果,大模型企业关心能效和成本,芯片公司看重技术与趋势,这一条链路上环环相扣,谁能把握技术趋势,谁就能真正胜券在握,看明白了这一点,我们或许就能明白为何有MatX和Taalas这样的公司涌现了。
英伟达的押注
比较有意思的是,英伟达虽然坐拥大半个AI芯片市场,但它也有自己的危机意识。此前虽传出消息,它将为部分厂商提供定制芯片服务,但在CEO黄仁勋的演讲中,英伟达再怎么放下身段,也不会完全迎合与满足客户需求,与上述的新兴芯片公司形成了鲜明反比。
英伟达的实际护城河是什么?毫无疑问是CUDA,黄仁勋将其视作成功的根本来源,这种生态绝非一朝一夕能够建立起来,英伟达想做和要做的,就是把CUDA铺设到无处不在。
因此,英伟达开始了自己的押注,根据金融数据公司Dealogic提供的数据,英伟达在2023年对30多家初创公司进行了投资,数量是上一年的三倍多。英伟达已发布的财报显示,截至今年1月末的上一财季,该公司对其他公司的投资总额约为15.5亿美元,远远超过一年前的3亿美元。
2023年,英伟达投资了大约11家AI基础设施提供商,包括数据分析公司Databricks Inc.,GPU云提供商CoreWeave Inc.和大语言模型提供商Mistral AI SAS,此外,英伟达还投资了像视频生成器Twelve Labs Inc.,聊天机器人创建者Cohere Inc.和机器人流程自动化初创公司Adept AI Labs Inc.这样的生成式AI公司。
英伟达的投资并不仅限于IT领域,还包括将AI应用于医疗保健的初创公司,它投资了八家药物发现初创公司,包括Generate Biomedicines Inc.和Genesis Therapeutics Inc.,这两家公司都在使用AI来发现新药。
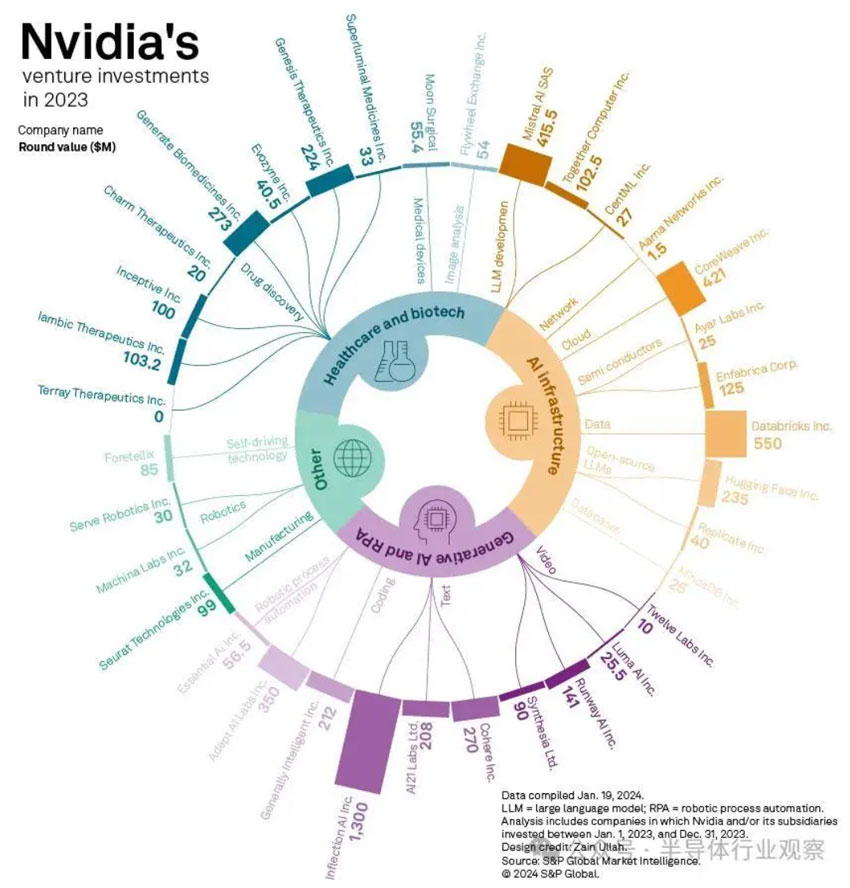
通过这些投资,英伟达不仅能够支持和利用这些初创公司在AI领域的创新,把市场蛋糕做大;还能与重要客户建立紧密联系,形成了一个良好的生态。这种策略可能使英伟达在竞争激烈的市场中获得优势,因为这些初创公司的成功可能进一步提升对英伟达产品的需求。同时,这也为英伟达提供了一个了解市场动向、技术创新和客户需求的窗口。
值得一提的是,根据英伟达2023财年的财报,其客户现可通过云服务,全面接触英伟达AI的各个层面:AI超级计算机、加速库软件以及预训练的生成式AI模型。用户可通过浏览器,通过英伟达DGX Cloud服务,接入英伟达DGX AI超级计算机。在AI平台软件层面,用户能够使用英伟达AI企业版,以训练和部署大型语言模型或其他AI工作负载。在AI模型即服务层面,英伟达为希望为其业务定制生成式AI模型和服务的企业客户提供NeMo和BioNeMo定制AI模型。
英伟达可能不会积极地提供定制芯片,但它却一定会乐于推销自己的定制生态,即使初期这些AI公司并不能提供什么实质性的回报,但它们所代表的未来趋势,正是英伟达所看重的,这种做法有点像是电脑上的付费软件,先提供一段时间的免费试用,等到用户养成使用习惯了,再开启收费模式。
而且英伟达这种抛砖引玉的做法不是没有成功的先例,OpenAI为什么会坚定不移地使用英伟达的芯片来训练模型,最早可以追溯到免费赠送的DGX-1,一台超算就撬动了百亿美元市场,这笔买卖怎么看这么划算。
写在最后
事到如今,AI芯片市场似乎已经分成了旗帜分明的三派:第一派也是最大的一派,当然是英伟达,靠着新鲜出炉的B200又能赚得盆满钵满,第二派是以博通为代表的定制派,比起英伟达,他们才更像是卖服务的,自己不生产芯片,帮企业造好芯片。
但这两派更多覆盖的还是那些中大型的巨头,只有它们才有财力和实力来训练自己的大模型,一部分初创AI公司实质上是被忽略了,即使英伟达豪掷数十亿美元,也只是覆盖了很小一部分初创公司,且纵使是巨头,在疯狂烧钱这件事上也已经出现了动摇,新的需求已经从幕后走向台前。
第三派如今开始崭露头角,喊出为每个大模型定制芯片的口号,意图就是打入英伟达和博通所不能顾及的市场,在AI浪潮中分得一杯羹。
你认为MatX和Taalas这样的公司会脱颖而出吗?