如何快速部署边缘就绪的机器学习应用
2022年08月18日 17:29 发布者:eechina
机器学习 (ML) 为创造智能产品提供了巨大的潜力,但神经网络 (NN) 建模和为边缘创建 ML 应用非常复杂且困难,限制了开发人员快速交付有用解决方案的能力。虽然现成的工具使 ML 模型的创建在总体上更加容易,但传统的 ML 开发实践并不是为了满足物联网 (IoT)、汽车、工业系统和其他嵌入式应用解决方案的独特要求而设计的。本文首先对 NN 建模进行简要介绍,然后介绍并描述如何使用 NXP Semiconductors 的综合 ML 平台让开发人员更有效地交付边缘就绪的 ML 应用。
NN 建模快速回顾
ML 算法为开发人员提供了截然不同的应用开发选择。开发人员不是编写软件代码来明确解决诸如图像分类等问题,而是提供一组数据——例如标注了所含实体的真实名称(或类别)的图像——来训练 NN 模型。训练过程使用各种方法来计算模型的参数,即每个神经元和每层的权重和偏置值,使模型能够对输入图像的正确类别提供相当准确的预测(图 1)。
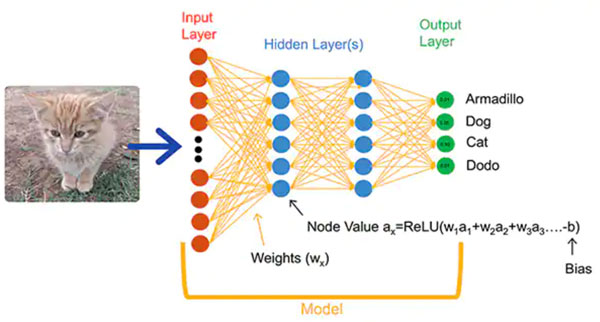
图 1:NN(例如此全连接网络)使用训练期间设置的权重和偏置参数对输入对象进行分类。(图片来源:NXP Semiconductors)
除图 1 所示的通用全连接 NN 外,ML 研究人员还发展了范围广泛的 NN 架构。例如,图像分类应用通常利用一种专门的架构——卷积神经网络 (CNN),它将图像识别分成两个阶段:初始阶段查找图像的关键特征,分类阶段预测它可能属于训练期间确定的多个类别中的哪一类(图 2)。
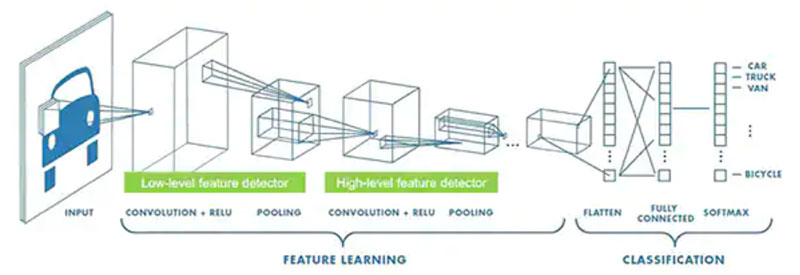
图 2:ML 专家使用专门的 NN 架构——例如该卷积神经网络 (CNN)——处理图像识别等特定任务。(图片来源:NXP Semiconductors)
尽管只有 ML 专家能够选择适当的模型架构和训练方案,但多种开源和商用工具的出现极大地简化了大规模部署的模型开发。如今,开发人员使用几行代码便可定义模型(清单 1),然后利用开源 Netron 模型查看器等工具生成模型的图形表示(图 3),以检查每一层的定义和连接。
def model_create(shape_in, shape_out):
from keras.regularizers import l2
tf.random.set_seed(RANDOM_SEED)
model = tf.keras.Sequential()
model.add(tf.keras.Input(shape=shape_in, name='acceleration'))
model.add(tf.keras.layers.Conv2D(8, (4, 1), activation='relu'))
model.add(tf.keras.layers.Conv2D(8, (4, 1), activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.MaxPool2D((8, 1), padding='valid'))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(64, kernel_regularizer=l2(1e-4), bias_regularizer=l2(1e-4), activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(32, kernel_regularizer=l2(1e-4), bias_regularizer=l2(1e-4), activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(shape_out, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
return model
清单 1:开发人员只需使用几行代码便可定义 NN 模型。(代码来源:NXP Semiconductors)

图 3:清单 1 中所定义模型的图形表示,由 Netron 查看器生成,可以帮助开发人员记录每一层的功能和连接。(图片来源:Stephen Evanczuk,使用清单 1 中的 NXP 模型源代码运行 Netron)
对于最终部署,其他工具会剥离仅训练期间需要的模型结构,并执行其他优化以创建高效的推理模型。
为智能产品开发基于 ML 的应用为什么如此困难
为物联网或其他智能产品定义和训练模型,与为企业级机器学习应用创建模型的工作流程相似。然而,尽管相似,但为边缘开发 ML 应用存在多种额外的挑战。除模型开发外,设计人员还面临一些常见的挑战,即开发所需的主应用以运行其基于微控制器 (MCU) 的产品。因此,将 ML 引入边缘需要管理两个相互关联的工作流程(图 4)。
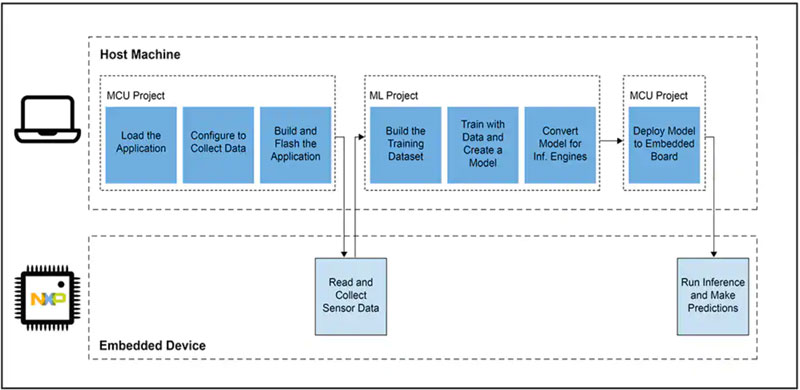
图 4:为边缘开发基于 ML 的应用时,除了典型的嵌入式 MCU 开发工作流程外,还需要一个 ML 工作流程来训练、验证和部署 ML 模型。(图片来源:NXP Semiconductors)
虽然嵌入式开发人员熟悉 MCU 项目的工作流程,但当开发人员努力创建一个优化的 ML 推理模型时,ML 项目会对基于 MCU 的应用提出额外的要求。事实上,ML 项目会极大地影响嵌入式设备的要求。模型执行通常涉及繁重的计算负载和存储器需求,这可能超出了物联网和智能产品中使用的微控制器资源的能力。为了减少资源需求,ML 专家会运用各种技术,例如:模型网络修剪、压缩、量化到较低精度,甚至使用单比特参数和中间值,以及其他方法。
然而,即使采用这些优化方法,开发人员仍可能发现常规微控制器在处理与 ML 算法相关的大量数学运算方面性能不足。另一方面,使用高性能应用处理器可以处理 ML 计算负载,但这种方法可能导致延迟增加和非确定性响应,影响其嵌入式设计的实时特性。
除了硬件选择方面的挑战,为边缘提供优化的 ML 模型还存在嵌入式应用开发所特有的额外挑战。为企业级 ML 应用开发的大量工具和方法,可能无法很好地扩展到嵌入式应用开发人员的应用和工作环境中。即使经验丰富的嵌入式应用开发人员,为了能够快速部署基于 ML 的设备,也可能需要在大量可用的 NN 模型架构、工具、框架和工作流程中竭力寻找有效的解决方案。
NXP 解决了边缘 ML 开发的硬件性能和模型实现两方面的问题。在硬件层面,NXP 的高性能 i.MX RT1170 跨界微控制器满足了边缘 ML 的广泛性能要求。为了充分利用这一硬件基础,NXP 的 eIQ(边缘智能)ML 软件开发环境和应用软件包提供了一种高效解决方案以创建边缘就绪的 ML 应用,它既适合没有经验的 ML 开发人员,也适合 ML 开发专家。
用于开发边缘就绪 ML 应用的高效平台
NXP 的 i.MX RT 跨界处理器兼具传统嵌入式微控制器的实时、低延迟响应与高性能应用处理器的执行能力。NXP 的 i.MX RT1170 跨界处理器系列集成了高能效 Arm®Cortex®-M4 和高性能 Arm Cortex-M7 处理器,以及运行严苛应用所需的大量功能块和外设,包括嵌入式设备中基于 ML 的解决方案(图 5)。
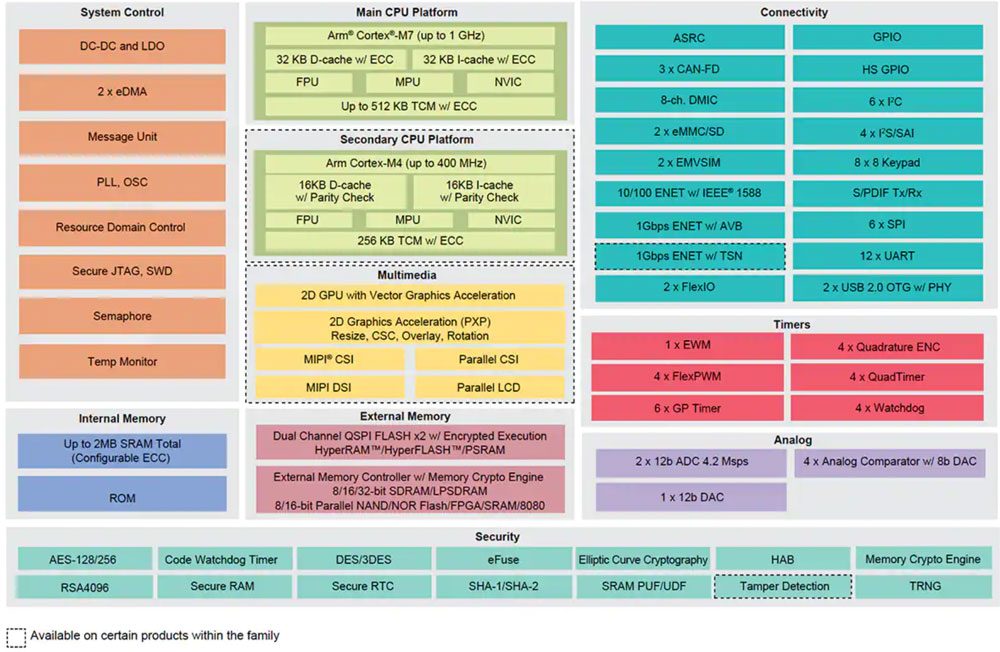
图 5:NXP 的 i.MX RT1170 跨界处理器兼具传统微控制器的高能效特性和应用处理器的强大处理能力。(图片来源:NXP Semiconductors)
NXP 的 eIQ 环境完全集成到 NXP 的 MCUXpresso SDK 和 Yocto 开发环境中,专门用于促进在利用 NXP 微处理器和微控制器构建的嵌入式系统上实现推理模型。eIQ 环境中包含 eIQ 工具包,后者通过多个工具支持“自带数据”(BYOD) 和“自带模型”(BYOM) 工作流程,这些工具包括 eIQ Portal、eIQ Model Tool 和命令行工具(图 6)。
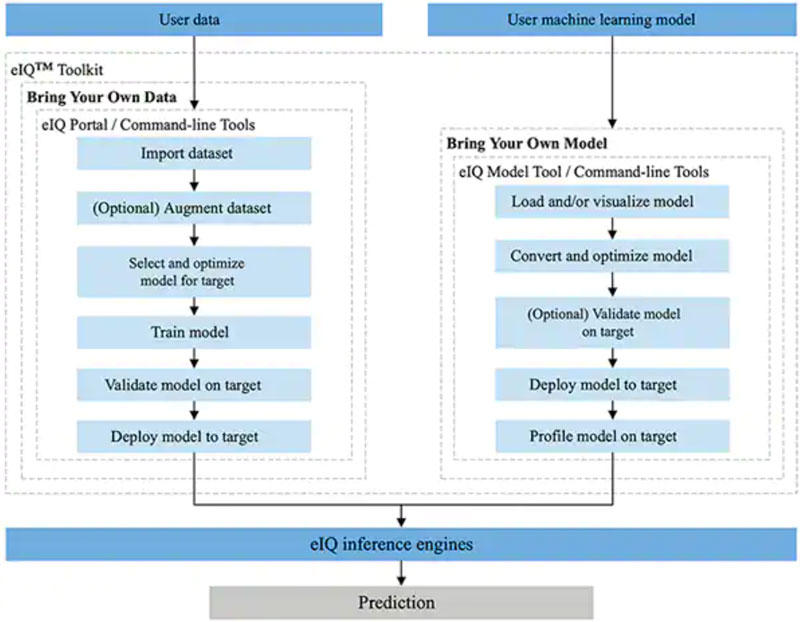
图 6:NXP 的 eIQ 工具包支持需要创建模型的 BYOD 开发人员和需要将自己的现有模型部署到目标系统的 BYOM 开发人员。(图片来源:NXP Semiconductors)
eIQ Portal 旨在同时支持 ML 模型开发专家和新手开发人员的 BYOD 工作流程,它提供了一个图形用户界面 (GUI),以帮助开发人员更轻松地完成模型开发工作流程的每个阶段。
在开发的初始阶段,eIQ Portal 的数据集管理工具帮助开发人员导入数据,从连接的相机中捕获数据,或从远程设备中捕获数据(图 7)。
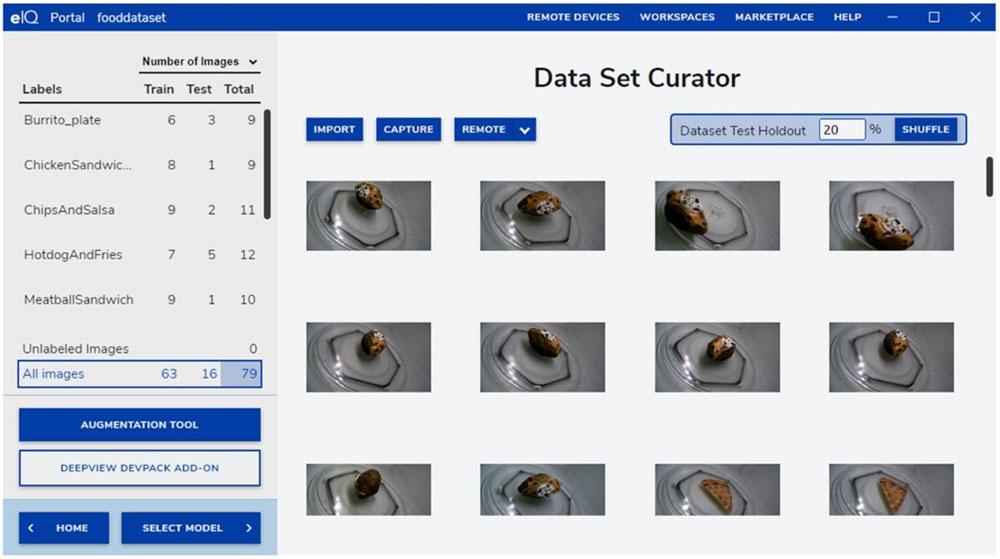
图 7:eIQ Portal 的数据集管理工具有助于执行准备训练数据这一关键任务。(图片来源:NXP Semiconductors)
开发人员使用数据集管理工具给数据集中的每个项目添加注释或标记,既可标记整幅图像,也可只标记指定边界框内包含的特定区域。扩展功能通过使图像模糊、添加随机噪声、更改特征(如亮度或对比度)及其他方法,帮助开发人员为数据集提供所需的多样性。
在下一阶段,eIQ Portal 帮助开发人员选择最适合应用的模型类型。对于不确定模型类型的开发人员,模型选择向导会根据应用类型和硬件基础引导开发人员完成选择过程。如果已经知道自己需要的模型类型,开发人员可以选择 eIQ 安装时提供的自定义模型或其他自定义实现方法。
eIQ Portal 引导开发人员完成下一关键训练步骤,并提供一个直观的图形用户界面,以便用户修改训练参数和查看模型预测精度随每个训练步骤的变化(图 8)。
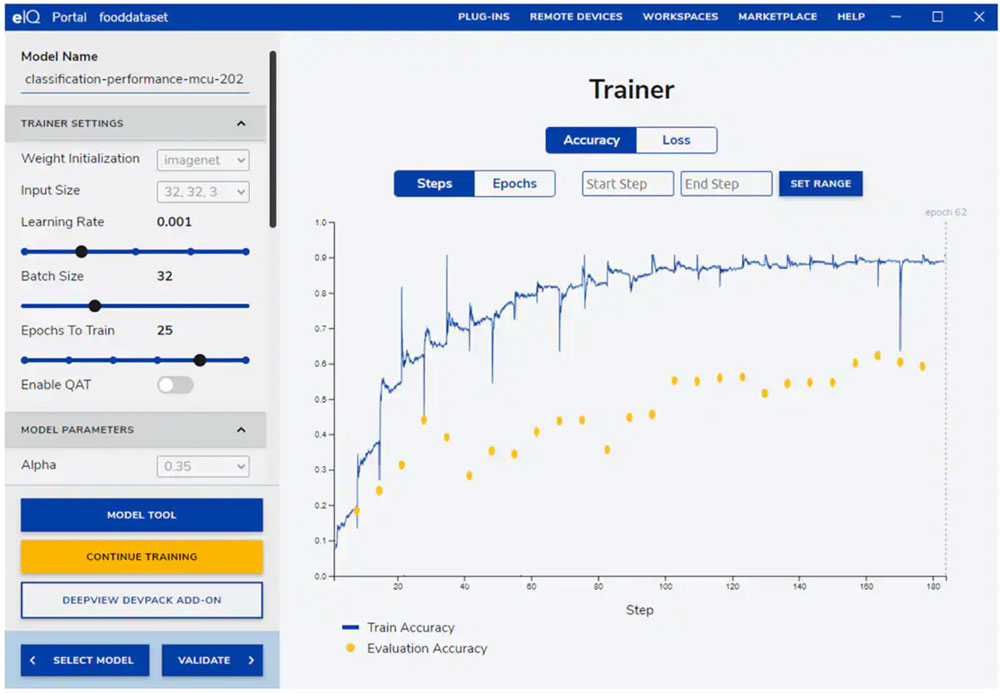
图 8:开发人员使用 eIQ Portal 的训练工具观察每一步带来的训练精度改善,并在必要时做出修改。(图片来源:NXP Semiconductors)
在下一步,eIQ Portal GUI 帮助开发人员验证模型。在此阶段,模型转换至目标架构上运行,以确定其实际性能。完成验证后,验证屏幕会显示混淆矩阵——这是一个基本的 ML 验证工具,允许开发人员将输入对象的实际类别与模型预测的类别进行比较(图 9)。
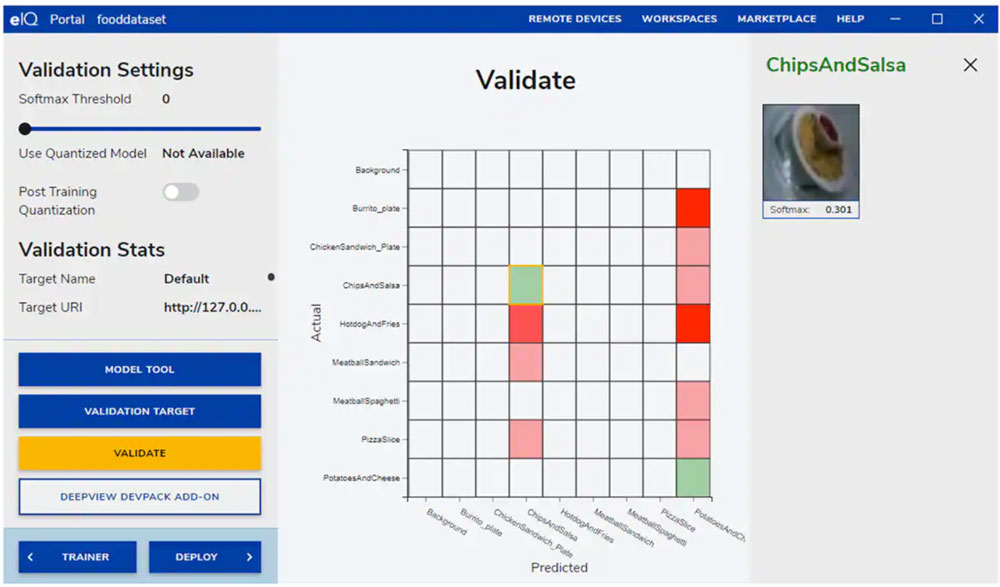
图 9:eIQ Portal 的验证工具为开发人员提供在目标架构上运行模型所产生的混淆矩阵。(图片来源:NXP Semiconductors)
对于最终部署,该环境允许开发人员根据处理器选择目标推理引擎,包括:
· Arm CMSIS-NN(通用微控制器软件接口标准,神经网络)— 为在 Arm Cortex-M 处理器内核上实现神经网络的性能最大化和内存占用最小化而开发的神经网络内核
· Arm NN SDK(神经网络,软件开发套件)— 一套工具和推理引擎,用于在现有神经网络框架和 Arm Cortex-A 处理器之间搭建桥梁等
· DeepViewRT — 用于 i.MX RT 跨界 MCU 的 NXP 专有推理引擎
· Glow NN — 基于 Meta 的 Glow (graph lowering) 编译器,由 NXP 针对 Arm Cortex-M 内核进行优化,使用 CMSIS-NN 内核的函数调用或 Arm NN 库(如有),或者从其自身的本地库编译代码
· ONXX Runtime — Microsoft Research 的工具,旨在针对 Arm Cortex-A 处理器优化性能
· 用于微控制器的 TensorFlow Lite — TensorFlow Lite 的较小版本,为在 i.MX RT 跨界 MCU 上运行机器学习模型而优化
· TensorFlow Lit — TensorFlow 的一个版本,为较小系统提供支持
对于 BYOM 工作流程,开发人员可以使用 eIQ Model Tool 直接进入模型分析和每层时间剖析。对于 BYOD 和 BYOM 工作流程,开发人员可以使用 eIQ 命令行工具访问工具功能以及非直接通过 GUI 提供的 eIQ 特性。
除了本文描述的特性外,eIQ 工具包还支持一系列广泛的功能,包括远远超出本文范围的模型转换和优化。然而,为了快速开发边缘就绪 ML 应用的原型,开发人员通常可以快速完成开发和部署,几乎不需要使用 eIQ 环境中许多较复杂的功能。事实上,NXP 的专业应用软件 (App SW) 包提供了完整的应用,开发人员可以使用这些应用立即开展评估,或将其作为自己定制应用的基础。
如何使用应用软件包快速评估模型开发
NXP 的应用软件包集生产就绪的源代码、驱动程序、中间件和工具于一体,提供完整的基于 ML 的应用。例如,NXP 的 ML 状态监测应用软件包为基于传感器输入确定复杂系统的状态这一常见问题提供了一个基于 ML 的快速解决方案(图 10)。
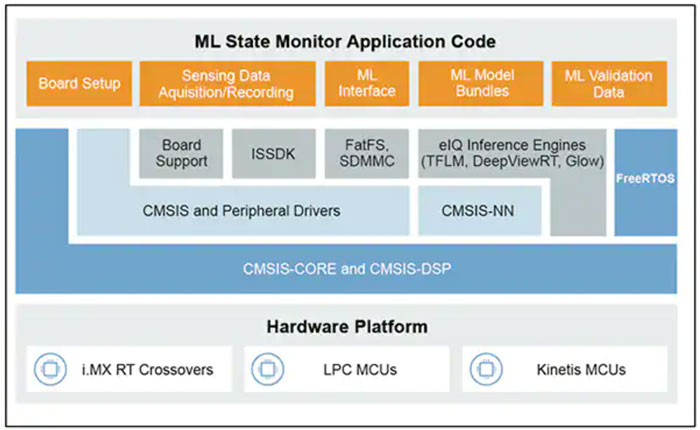
图 10:开发人员可以使用 NXP 的应用软件包(如 ML 状态监测应用软件包)立即开展评估,或将其作为定制代码开发的基础。(图片来源:NXP Semiconductors)
ML 状态监测应用软件包实现了一个完整的应用解决方案,可检测风扇工作在四种状态中的哪一种状态:
· ON
· OFF
· CLOGGED,当风扇开启但气流被阻挡时
· FRICTION,当风扇开启,但一个或多个风扇叶片在运行过程中遇到过大摩擦时
对于模型开发人员,同样重要的是,ML 状态监测应用软件包除包括 ML 模型外,还包括一个完整数据集,它代表了风扇在这四种状态下运行的加速度计读数。
开发人员可以研究 ML 状态监测应用软件包提供的代码、模型和数据,以了解如何使用传感器数据训练模型,创建推理模型,并针对验证传感器数据集验证推理。事实上,NXP 的应用软件包中包含的 ML_State_Monitor.ipynb Jupyter Notebook 提供了一个开箱即用的工具,支持在任何硬件部署之前研究模型开发工作流程。
Jupyter Notebook 是一个基于浏览器的互动式 Python 执行平台,允许开发人员立即查看 Python 代码的执行结果。运行 Jupyter Notebook 会生成一个 Python 代码块,紧接着出现该代码块的运行结果。这些结果不是简单的静态展示,而是通过运行代码得到的实际结果。例如,开发人员运行 NXP 的 ML_State_Monitor.ipynb Jupyter Notebook 时,可以立即查看输入数据集的摘要(图 11)。
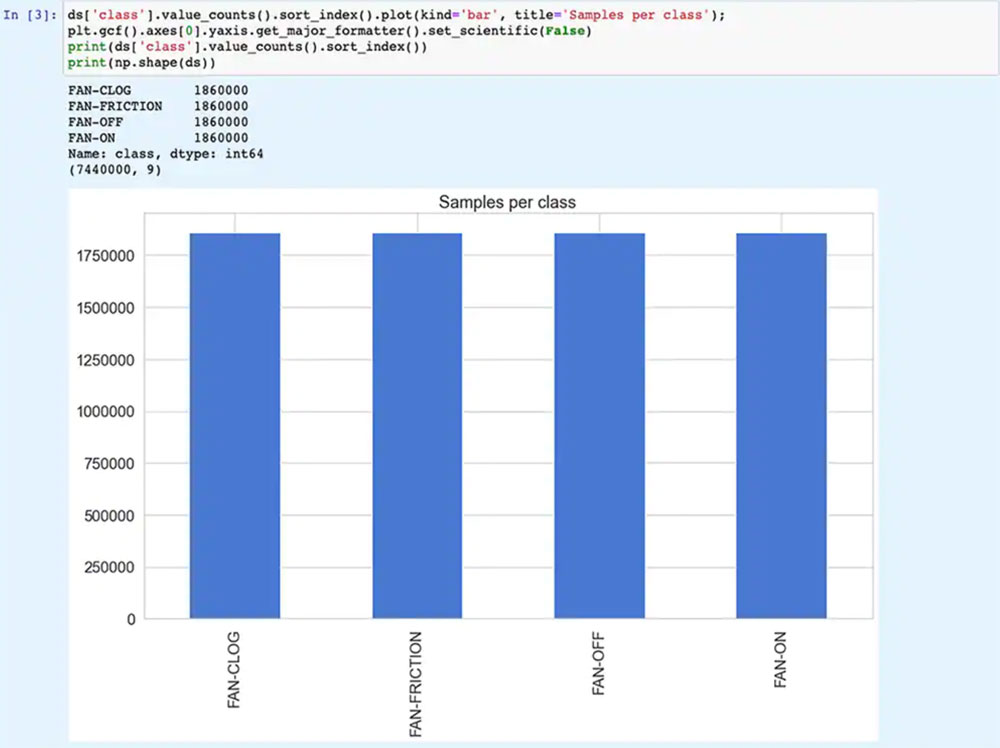
图 11:NXP 的 ML_State_Monitor.ipynb Jupyter Notebook 让开发人员以交互方式完成神经网络模型开发工作流程,查看 ML 状态监测应用软件包中提供的训练数据。[注:为展示目的,代码被截断。](图片来源:Stephen Evanczuk,运行 NXP 的 ML_State_Monitor.ipynb Jupyter Notebook)
Notebook 中的下一部分代码为用户提供了输入数据的图形显示,以时间序列和频率的单独图形呈现(图 12)。
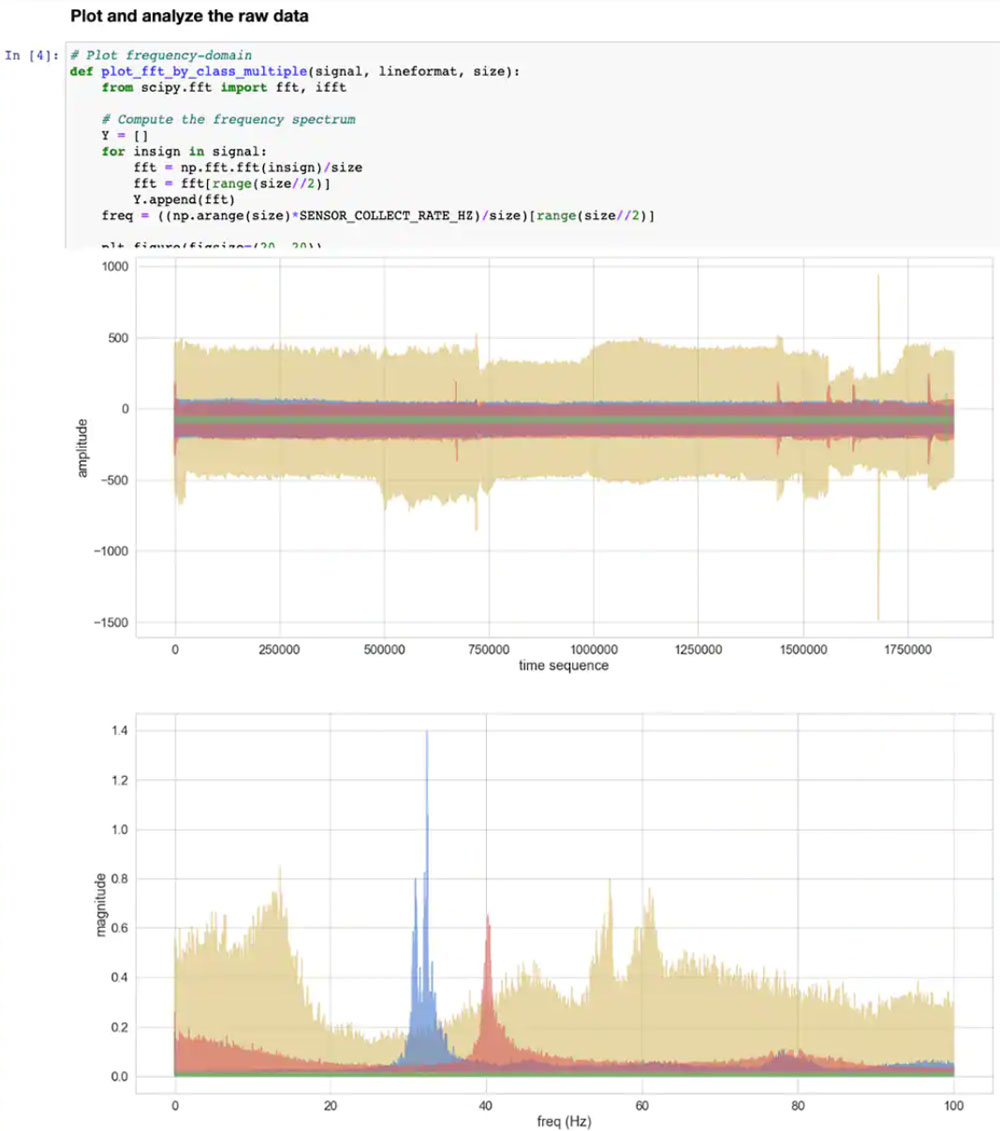
图 12:Jupyter Notebook 为开发人员提供了风扇状态样本数据集的时间序列和频率显示(OFF:绿色;ON:红色;CLOGGED:蓝色;FRICTION:黄色)。[注:为展示目的,代码被截断。](图片来源:Stephen Evanczuk,运行 NXP 的 ML_State_Monitor.ipynb Jupyter Notebook)
其他代码部分提供了进一步的数据分析、规一化、整形和其他准备工作,直至代码执行到清单 1 中显示的模型创建函数定义 model_create()。接下来的代码部分将执行此 model_create() 函数,并打印出摘要以供快速验证(图 13)。

图 13:NXP 的 ML_State_Monitor.ipynb Jupyter Notebook 创建模型(如清单 1 所示)并显示模型摘要信息。(图片来源:Stephen Evanczuk,运行 NXP 的 ML_State_Monitor.ipynb Jupyter Notebook)
在部分模型训练和评估代码之后,ML_State_Monitor.ipynb Jupyter Notebook 显示完整数据集、训练数据集和验证数据集(从训练数据集中排除的数据集的子集)的每个混淆矩阵。在这种情况下,完整数据集的混淆矩阵展现出良好的精度和一定的误差,其中最明显的是模型将一小部分数据集混淆为处于 ON 状态,而根据原始数据集的注释,它们实际上处于 CLOGGED 状态(图 14)。
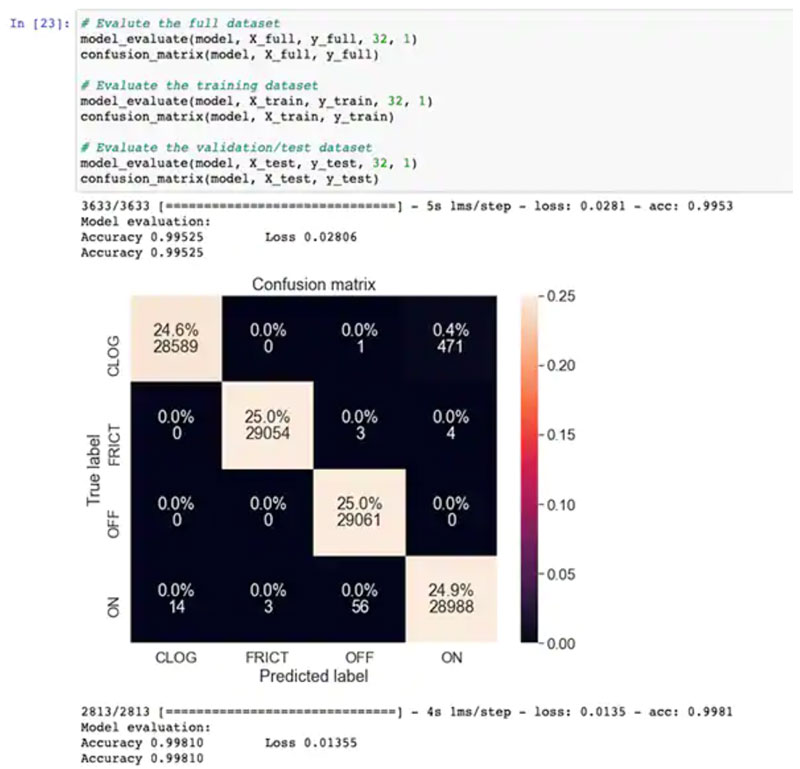
图 14:开发人员可以查看混淆矩阵,这里以完整数据集的混淆矩阵为例。(图片来源:Stephen Evanczuk,运行 NXP 的 ML_State_Monitor.ipynb Jupyter Notebook)
在后面的代码部分,模型被导出为几种不同的模型类型和格式,由 eIQ 开发环境支持的各种推理引擎使用(图 15)。
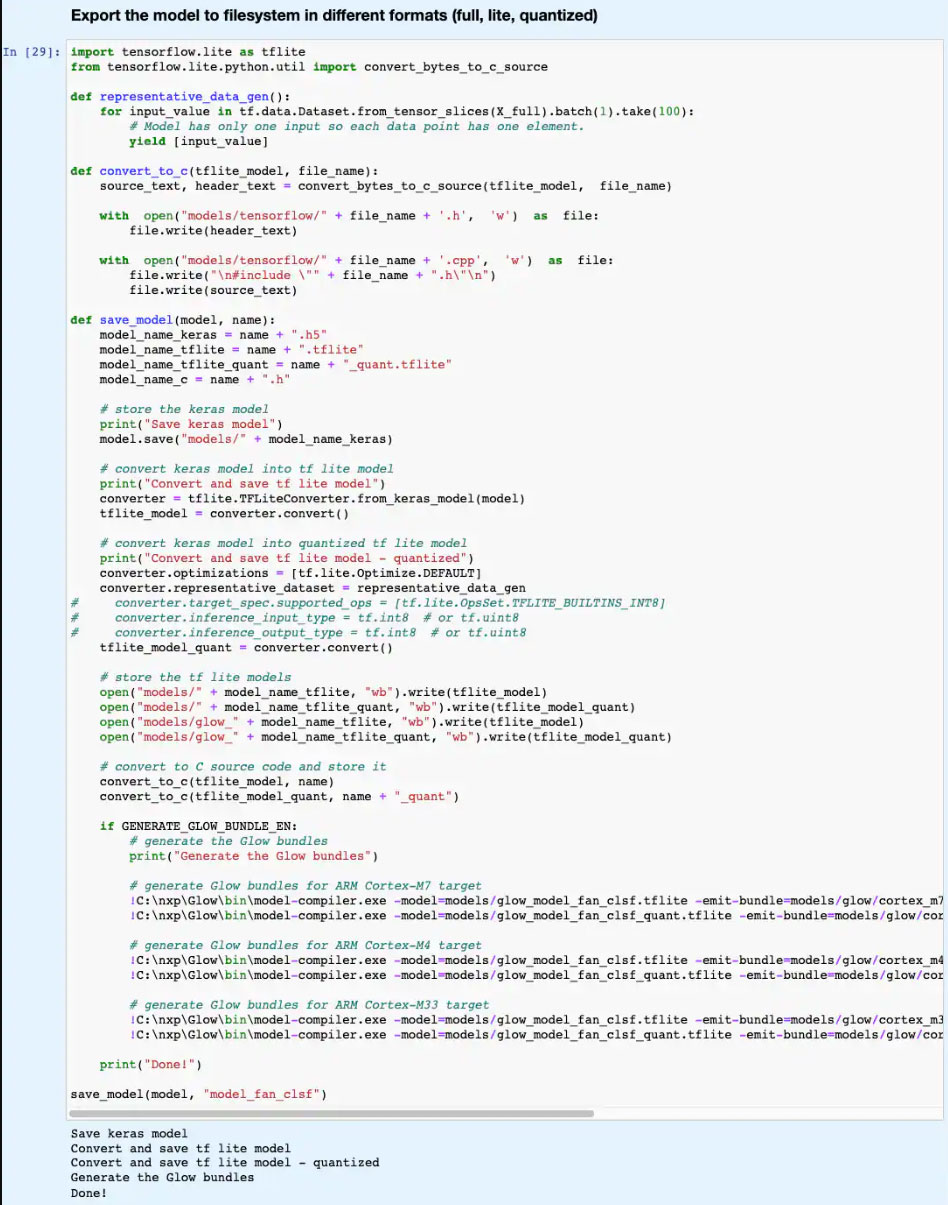
图 15:NXP 的 ML_State_Monitor.ipynb Jupyter Notebook 演示了开发人员如何以几种不同的模型类型和格式保存其训练模型。(图片来源:Stephen Evanczuk,运行 NXP 的 ML_State_Monitor.ipynb Jupyter Notebook)
推理引擎的选择对于满足特定性能要求至关重要。对于该应用,NXP 测量了以几种不同推理引擎为目标的模型大小、代码大小和推理时间(对单一输入对象完成推理所需的时间),一个以 996 MHz 运行,一个以 156 MHz 运行(图 16 和 17)。
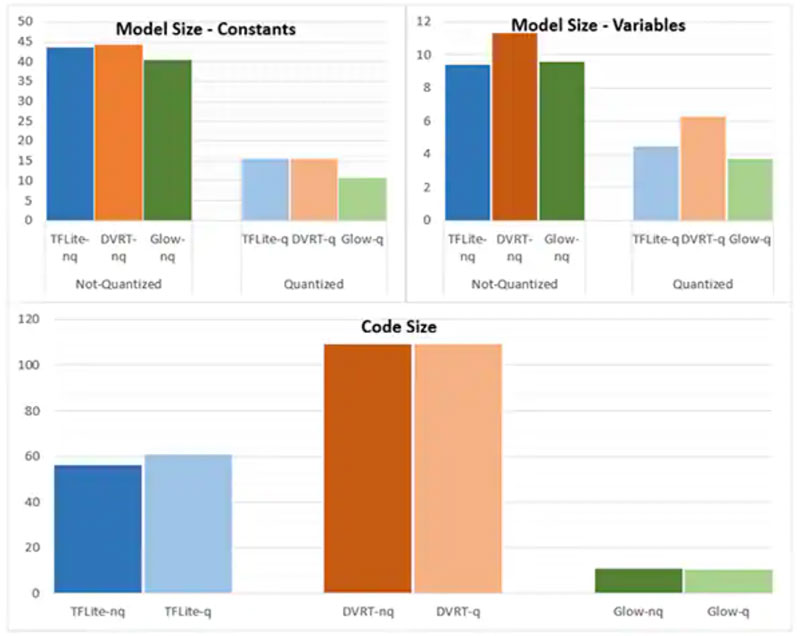
图 16:模型类型的选择可能会显著影响模型大小,不过这里显示的巨大差异可能不适用于较大的模型。(图片来源:NXP Semiconductors)
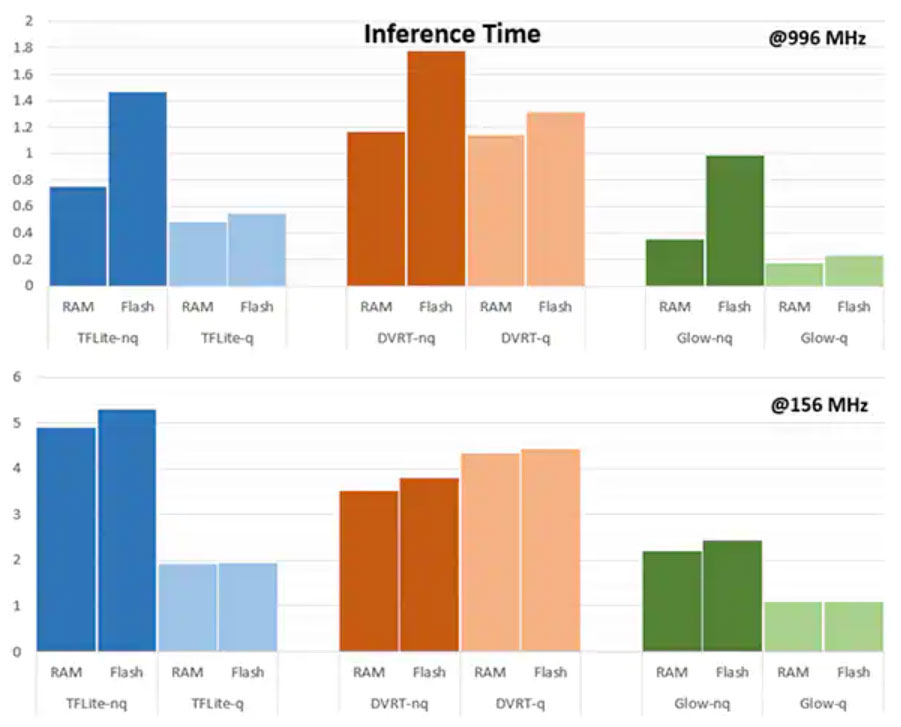
图 17:根据情况不同,评估输入对象所用的推理时间可能相差很大:是从 RAM 加载还是从闪存加载,或者处理器是以 996 MHz 的较高频率运行还是以 156 MHz 的频率运行。(图片来源:NXP Semiconductors)
正如 NXP 指出的那样,此样例应用使用的是一个非常小的模型,所以这些数字的差异相当明显,但对于复杂分类所用的大型模型,差异可能要小得多。
构建用于状态监测的系统解决方案
除了用于交互式探索模型开发工作流程的 Jupyter Notebook,NXP 的 ML 状态监测应用软件包还提供完整的源代码,用于在 NXP 的 MIMXRT1170-EVK 评估板上实现设计。评估板围绕 NXP 的 MIMXRT1176DVMAA 跨界 MCU 构建,提供一个全面的硬件平台,并配备了额外的存储器和多个接口(图 18)。
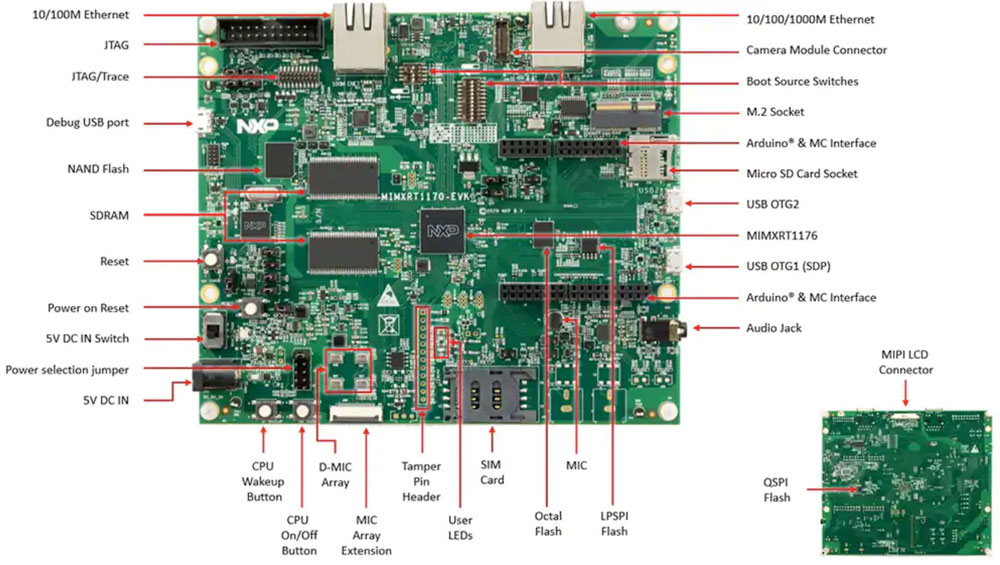
图 18:NXP 的 MIMXRT1170-EVK 评估板提供一个全面的硬件平台,支持开发基于 NXP 的 i.MX RT1170 系列跨界 MCU 的应用。(图片来源:NXP Semiconductors)
将 MIMXRT1170-EVK 评估板与可选的 NXP FRDM-STBC-AGM01 传感器板、Arduino 扩展板和合适的 5 V 无刷直流风扇(如 Adafruit 的 4468)堆叠起来,开发人员便可使用 NXP 的风扇状态应用来预测风扇的状态(图 19)。

图 19:在 MIMXRT1170-EVK 评估板上构建一个简单堆叠,开发人员便可测试 NXP 风扇状态样例应用。(图片来源:NXP Semiconductors)
借助 MCUXpresso 集成开发环境 (IDE),开发人员可以配置应用以简单地获取和存储风扇状态数据,或立即使用 TensorFlow 推理引擎、DeepViewRT 推理引擎或 Glow 推理引擎对获取的数据运行推理(清单 2)。
/* Action to be performed */
#define SENSOR_COLLECT_LOG_EXT 1 // Collect and log data externally
#define SENSOR_COLLECT_RUN_INFERENCE 2 // Collect data and run inference
/* Inference engine to be used */
#define SENSOR_COLLECT_INFENG_TENSORFLOW 1 // TensorFlow
#define SENSOR_COLLECT_INFENG_DEEPVIEWRT 2 // DeepViewRT
#define SENSOR_COLLECT_INFENG_GLOW 3 // Glow
/* Data format to be used to feed the model */
#define SENSOR_COLLECT_DATA_FORMAT_BLOCKS 1 // Blocks of samples
#define SENSOR_COLLECT_DATA_FORMAT_INTERLEAVED 2 // Interleaved samples
/* Parameters to be configured by the user: */
/* Configure the action to be performed */
#define SENSOR_COLLECT_ACTION SENSOR_COLLECT_RUN_INFERENCE
#if SENSOR_COLLECT_ACTION == SENSOR_COLLECT_LOG_EXT
/* If the SD card log is not enabled the sensor data will be streamed to the terminal */
#define SENSOR_COLLECT_LOG_EXT_SDCARD 1 // Redirect the log to SD card, otherwise print to console
清单 2:开发人员可以通过修改 sensor_collect.h 头文件中包含的定义,轻松配置 NXP 的 ML 状态监测样例应用。(代码来源:NXP Semiconductors)
该应用的工作流程简单明了。main.c 中的主例程创建一个名为 MainTask 的任务,后者是位于 sensor_collect.c 模块中的一个例程。
void MainTask(void *pvParameters)
{
status_t status = kStatus_Success;
printf("MainTask started\r\n");
#if !SENSOR_FEED_VALIDATION_DATA
status = SENSOR_Init();
if (status != kStatus_Success)
{
goto main_task_exit;
}
#endif
g_sensorCollectQueue = xQueueCreate(SENSOR_COLLECT_QUEUE_ITEMS, sizeof(sensor_data_t));
if (NULL == g_sensorCollectQueue)
{
printf("collect queue create failed!\r\n");
status = kStatus_Fail;
goto main_task_exit;
}
#if SENSOR_COLLECT_ACTION == SENSOR_COLLECT_LOG_EXT
uint8_t captClassLabelIdx;
CAPT_Init(&captClassLabelIdx, &g_SensorCollectDuration_us, &g_SensorCollectDuration_samples);
g_SensorCollectLabel = labels;
if (xTaskCreate(SENSOR_Collect_LogExt_Task, "SENSOR_Collect_LogExt_Task", 4096, NULL, configMAX_PRIORITIES - 1, NULL) != pdPASS)
{
printf("SENSOR_Collect_LogExt_Task creation failed!\r\n");
status = kStatus_Fail;
goto main_task_exit;
}
#elif SENSOR_COLLECT_ACTION == SENSOR_COLLECT_RUN_INFERENCE
if (xTaskCreate(SENSOR_Collect_RunInf_Task, "SENSOR_Collect_RunInf_Task", 4096, NULL, configMAX_PRIORITIES - 1, NULL) != pdPASS)
{
printf("SENSOR_Collect_RunInf_Task creation failed!\r\n");
status = kStatus_Fail;
goto main_task_exit;
}
#endif
清单 3:在 NXP 的 ML 状态监测样例应用中,MainTask 调用一个子任务来获取数据或运行推理。(代码来源:NXP Semiconductors)
MainTask 先执行各种初始化任务,再启动两个子任务中的一个,具体哪一个取决于用户在 sensor_collect.h 中的设置:
如果 SENSOR_COLLECT_ACTION 被设置为 SENSOR_COLLECT_LOG_EXT,则 MainTask 启动子任务 SENSOR_Collect_LogExt_Task(),收集数据并将其存储在 SD 卡上(如已配置)
如果 SENSOR_COLLECT_ACTION 被设置为 SENSOR_COLLECT_RUN_INFERENCE,则 MainTask 启动子任务 SENSOR_Collect_RunInf_Task(),针对所收集的数据运行 Sensor_collect.h 中定义的推理引擎(Glow、DeepViewRT 或 TensorFlow);如果定义了 SENSOR_EVALUATE_MODEL,则还会显示相应的性能和分类预测
if SENSOR_COLLECT_ACTION == SENSOR_COLLECT_LOG_EXT
void SENSOR_Collect_LogExt_Task(void *pvParameters)
{
while (1)
{
bufSizeLog = snprintf(buf, bufSize, "%s,%ld,%d,%d,%d,%d,%d,%d,%d\r\n", g_SensorCollectLabel, (uint32_t)(sensorData.ts_us/1000),
sensorData.rawDataSensor.accel, sensorData.rawDataSensor.accel, sensorData.rawDataSensor.accel,
sensorData.rawDataSensor.mag, sensorData.rawDataSensor.mag, sensorData.rawDataSensor.mag,
sensorData.temperature);
#if SENSOR_COLLECT_LOG_EXT_SDCARD
SDCARD_CaptureData(sensorData.ts_us, sensorData.sampleNum, g_SensorCollectDuration_samples, buf, bufSizeLog);
#else
printf("%.*s", bufSizeLog, buf);
}
vTaskDelete(NULL);
}
#elif SENSOR_COLLECT_ACTION == SENSOR_COLLECT_RUN_INFERENCE
void SENSOR_Collect_RunInf_Task(void *pvParameters)
{
while (1)
{
/* Run Inference */
tinf_us = 0;
SNS_MODEL_RunInference((void*)g_clsfInputData, sizeof(g_clsfInputData), (int8_t*)&predClass, &tinf_us, SENSOR_COLLECT_INFENG_VERBOSE_EN);
#if SENSOR_EVALUATE_MODEL
/* Evaluate performance */
validation.predCount++;
if (validation.classTarget == predClass)
{
validation.predCountOk++;
}
PRINTF("\rInference %d?%d | t %ld us | count: %d/%d/%d | %s ",
validation.classTarget, predClass, tinf_us, validation.predCountOk,
validation.predCount, validation.predSize, labels);
tinfTotal_us += tinf_us;
if (validation.predCount >= validation.predSize)
{
printf("\r\nPrediction Accuracy for class %s %.2f%%\r\n", labels,
(float)(validation.predCountOk * 100)/validation.predCount);
printf("Average Inference Time %.1f (us)\r\n", (float)tinfTotal_us/validation.predCount);
tinfTotal_us = 0;
}
#endif
}
exit_task:
vTaskDelete(NULL);
}
#endif /* SENSOR_COLLECT_ACTION */
清单 4:NXP 的 ML 状态监测样例应用演示了获取传感器数据和对获取的数据运行所选推理引擎的基本设计模式。(代码来源:NXP Semiconductors)
由于 NXP 的 ML 状态监测应用软件包提供了完整的源代码以及全套必需的驱动程序和中间件,因此开发人员可以轻松扩展该应用以增加特性,或将其作为起点来开发自己的定制应用。
总结
在物联网和其他应用中的智能产品的边缘实施 ML 可以提供一系列强大的功能,但现有 ML 工具和方法大多是为企业级应用而开发的,边缘 ML 开发人员使用起来往往很吃力。有了由跨界处理器和专门的模型开发软件组成的 NXP 开发平台,无论 ML 专家还是几乎没有 ML 经验的开发人员都能更有效地创建专门设计的 ML 应用,以满足对高效边缘性能的要求。