基于深度学习生成自己的图像问答模型
2021年06月22日 14:47 发布者:洞幺邦
基于深度学习生成自己的图像问答模型 VQA 是什么?:Visual Question Answering我们可以这样定义:“视觉问答(VQA)是一种系统,它将图像和自然语言问题作为输入, 并生成自然语言答案作为输出。”就和下面这张图片类似:输入这张图片和问题,我们期望的答案或许是 black and banana。

VQA 的应用:盲人的视觉问答,搜索引擎(不单单是以图搜图或者以文字搜信息,而是结合 图+问题,搜索出答案),智能驾驶领域,医疗问答等领域。
VQA 的框架:视觉问题回答可以分为两个部分,即图像和文本。使用卷积神经网络(用于图像数据)和循环神经网络(用于文本数据)来表示神经网络方法来解决这个问题。主要思想是从 CNN 得到图像的特征,从 RNN 得到文本的特征,最后将它们组合起来,通过一些完全连接的层来生成答案。
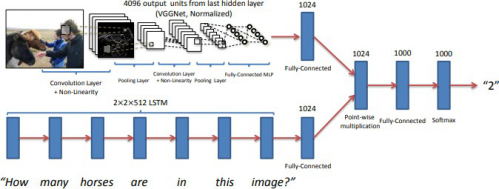 编辑搜图
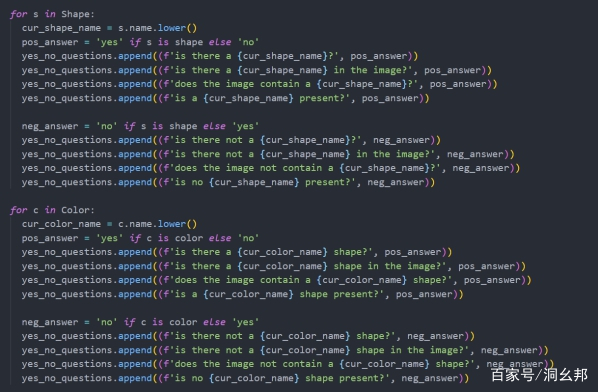
编辑搜图(这是从 VQA 经典论文中截取的图片,虽然模型不完全一致,但思路是一样的)(Image Source: https://arxiv.org/pdf/1505.00468.pdf)本文将介绍一下基于深度学习的easy-VQA数据集和训练预测过程。1. 基于简单图形生成 easy-VQA 数据集总共考虑了三种图形:圆形 (circle),矩形 (rectangle) 和三角形 (triangle) 和八种颜色,将它们两两组合,在 64 ∗ 64 的画布范围内,随机生成不同大小,不同颜色的图形;由于生成图像时,可以根据该图像的特征生成特定的问题,基于这种思路,我设计了若干关于图形和颜色的问题:


生成的数据集大约有 5k 张图片 50k 个问题,答案分类有 13 种:分别是yes/or 问题,颜色问题和图形问题。YES/NO: Yes, NoShapess: Circle, Rectangle, TriangleColors: Red, Green, Blue, Black, Gray, Teal, Brown, Yellow2. 在 easy-VQA 上实现图像问答架构
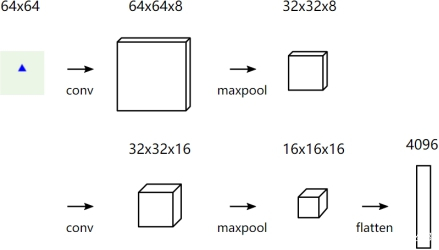
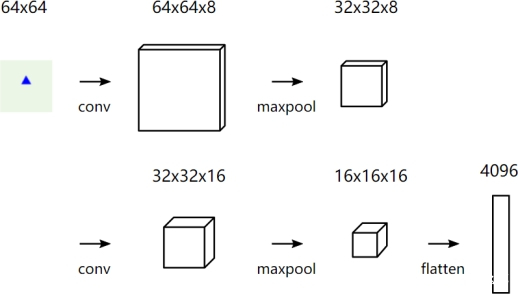
首先输入的图像是64∗64的,对图像进行若干次卷积核池化操作,可以生成固定长度的向量,这里设置为4096维。samepadding进行填充之后,对该图片使用3∗3的卷积核进行卷积,得到64∗64∗8;然后经过一层最大池化maxpooling得到32∗32∗8;经过另外一层有16个卷积核的卷积和池化过程,最后将图片的特征表示转化成 4096 维的固定长度的向量。图 3 2: 图像处理模型鉴于easy-VQA的实验性质,对于它的图片和问题的设计都比较简单,问题来自一组固定的模板,为了训练时间和demo性质的考虑,对于问题的处理,首先使用词袋模型BOW将每个单词转化成一个向量。BOW表示通过计算每个单词在文本中出现的次数,将任何文本字符串转换为固定长度的向量。然后将这些向量输入全连接的前馈神经网络fully-connected(FC),最终得到问题特征的向量表示。最后将图片特征向量和问题特征向量拼接起来,通过 softmax 分类,在由13 种答案组成的答案候选集中选择概率最高的答案作为输出。在验证集上的可以达到不错的准确率。
 编辑搜图
编辑搜图
可以看到训练的效果还是不错的:损失率逐渐下降,准确率逐渐上升;同时模型也并没有过拟合,训练和验证的损失率准确率都比较接近。

 编辑搜图
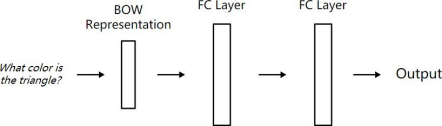
编辑搜图问题模型,因为问题比较简单,使用词袋模型即可,后面加两层全连接层,将问题转化成了向量。
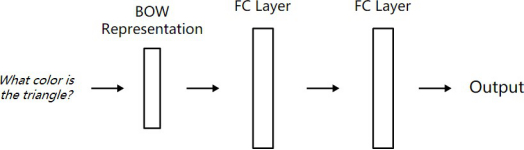 编辑搜图
编辑搜图将图片向量和问题向量融合,输入进 softmax 分类即可。
 编辑搜图
编辑搜图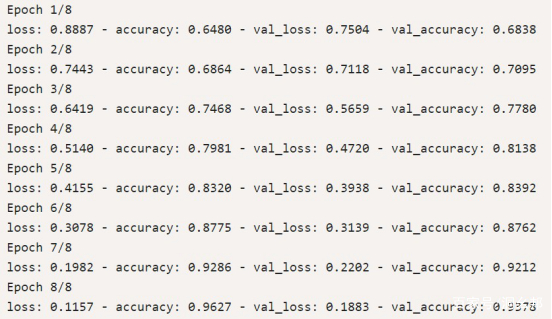 编辑搜图
编辑搜图最后可以看到达到了 93.8 的 accuracy。