基于复杂度的嵌入式软件功耗模型
2010年11月16日 16:17 发布者:eetech
系统功耗是嵌入式系统的一个重要方向,功耗很大程度上取决于执行的软件。传统的底层指令级模型功耗分析方法虽然能比较准确地估算出嵌入式系统的功耗,但是这种方法所需要的时间过长。本文介绍一种高层嵌入式软件功耗分析估测方法,以对象函数所使用的算法的复杂度来对该函数构建功耗模型,从而根据此功耗模型能快速估算出该函数在各种输入情形下的功耗情况。 1 嵌入式软件功耗
嵌入式系统的功耗主要来自微处理器的功耗与外围部件的功耗。虽然能量的水泵最终发生在底层硬件,但是微处理器的功耗很大程度上取决于其所执行的软件。因此,对嵌入式系统的功耗分析越来越多地转移到软件的角度上来,将能量的消耗过程视作软件执行过程。
目前的嵌入式软件功耗分析大多数都是基于指令级功耗模型的分析方法。在这种模型中,嵌入式软件程序的功耗由单条指令的基本功耗开销、连续执行不同类型的指令造成的功耗开销以及额外的功耗开销(如流水线断流、Cache不命中)等构成。虽然这种底层的嵌入式软件功耗的分析方法的准确性较高,但是其分析过程需要在特定微处理器平台上将程序翻译成汇编指令,然后通过逐条指令功耗分析和综合因素考虑,最后才能估算出该程序在某种微处理器上执行的系统功能,需要相当长的分析时间。
2 基于复杂度的嵌入式软件功耗模型
针对指令级功耗模型的瓶颈,本文介绍一种基于复杂度的嵌入式软件功耗模型,利用现有条件能快速估算出某函数的功耗情况。
在嵌入式软件应用中大量使用的多媒体计算和其它数据密集型计算中,经常用到诸如查找、排序、矩阵运算等算法。由于这些算法的平均复杂度都是已知的,因此复杂度成为这些嵌入式软件程序的一个重要特征,同样也能够成为分析和估测嵌入式软件功耗的一种重要依据。基于复杂度的嵌入式软件功耗模型以具体函数所使用的算法的复杂度为建模的参数,选取该函数的典型输入,并利用现有指令级模型分析方法获得该函数在这些典型输入情况下的功耗,利用回归算法出该函数软件功耗模型的系数,从而获得完事的该函数软件功耗模型,并可以用于快速估算该函数在任何输入情况下的软件功耗。
在某函数的算法复杂度是已知的或较容易获得的情况下,假设该函数的执行所需功耗与其复杂度有关,则可以使用一个线性公式来描述该函数的软件功耗:
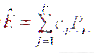
其中Pj为模型的参数与函数的算法复杂度与函数的输入相关;cj为相应的系数;p是参数个数。
构建模型的第一步是决定描述功耗模型的参数Pj。参数的选择与具体的函数所使用的算法密度相关。几种比较常见的算法的功耗模型可以表1中的线性公式来描述。
表1 基于复杂度的软件功耗模型
算 法
平均复杂度
软件功耗宏模型
数组求和
O(n)
c1+c2N
插入排序
O(n2)
c1+c2N+c3N2
快速排序
O(nlog2n)
c1+c2N+c3Nlog2N
参数确定之后,必须找到相应的系数cj,这是整个算法中最重要的步骤。一旦获得系数cj后,就可以利用这些系统估算出该函数在任何输入情况下的功耗。
要算出系数,首先要确定该函数的典型输入集合S={I1,I2,…,In},S中的每个Ii都与该函数一组模型参数Pj相对应。n个Ii对应形成一个该函数的模型参数矩阵。
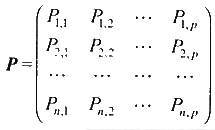
通过底层指令级模型分析得到该函数在每组参数Ii情况下的功耗。

其中然后通过矩阵运算即可回归出参数向量C。
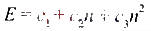
3 基于复杂度的插入排序函数软件功耗建模
以下将以Integrator/CM7TDMI评估板的ARM7TDMI微处理器为基础,对插入排序函数来构建基于复杂度的嵌入式软件功耗模型。
假设某运行在ARM7TDMI处理器上的函数,对一长度为n的整形数组a使用简单插入排序算法进行排序。算法的C语言代码与其经过ARMCC编译器编译后的汇编代码如下:
void ins_sort(int a[],int n){
int x,i,j;
for(i=1;i
其中,n为数组的长度,E为在输入数组长度的n的情况下函数的功耗。
3.2 获得系数cj
在这一步骤中,主要以Integrator/CM7TDMI评估板的三段流水线、不设cache的ARM7TDMI处理器的指令级功耗模型为基础,分析该插入排序函数分别在输入数组长度n=10、20、40情况下的功耗情况,并通过回归法获得系数cj。
在该指令级功耗模型中,指令执行的功耗主要来自两个部分:执行单条指令引起的功耗(base cost)与连续执行不同类型的指令导致处理器状态改变所引起的额外功耗(inter-instruction cost)。其公式如下:
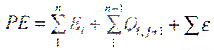
其中,Ei为执行第I条指令的基本指令功耗(表2),Oij为连续执行第I条和第I指令引起的额外功耗(表3),ε为流水线断流引起的功耗(表4)。
表2 Integrator/CM7TDMI ARM7TDMI基本指令功耗
Instruction
E/nJ
Instruction
E/nJ
ADD R2,R0,R1
0.710
KDR R2,
2.774
AND R2,R0,R1
0.856
STR R2,
1.961
ORR R2,R0,R1
0.907
MUL R2,R0,R1
2.768
ORRS R2,R0,R1
0.967
MLA R2,R0,R1,R0
3.748
MOV R2,R1
0.935
CMP R0,R1
0.751
MOV R0,R0
0.903
SWP R2,R0,
3.917
ADD R2,R0,R1,ASR R3
2.137
MRS R2,CPSR
0.977
B lable
3.095
MSR CPSR_f,R2
1.143
表3 执行连接两条源操作数类型不同指令的功耗
Instr1/Instr2
SHIFT_REG
SHIFT_IMM
REG
IMM
SHIFT_REG
-0.332
-0.215
-0.232
-0.159
SHIFT_IMM
-0.269
-0.177
-0.165
-0.103
REG
-9.02E-02
-5.98E-02
-0.186
-0.200
IMM
-0.141
-5.35E-02
-9.08E-02
-7.53E-02
表4 流水线断流引起的功耗
Instruction type
Energy cost/nJ
Any
2.04
根据以上表中的数据结合该函数汇编指令,得出该插入排序函数的指令级功耗分析情况(表5)。
表5 简单插入排序指令级功耗分析
指 令
Base cost
Inter cost
Stall cost
MOV r3,#1
0.930
-
-
B |L1,56|
3.100
-0.075
2.04
MOV r2,#0
0.930
-0.032
-
B |L1,44|
3.100
-0.075
2.04
LDR r12,
3.270
-0.032
-
LDR lr,
3.270
-0.177
-
CMP r12,lr
0.830
-0.165
2.04
STRIT r12,
2.480
-0.060
-
STRLT lr,
2.480
-0.177
-
CMP r2,r2,#1
1.590
-0.103
-
CMP r2,r3
0.830
-0.091
2.04
BLT |L1.20|
3.100
-0.060
2.04
ADD r3,r3,#1
1.590
-0.075
-
CMP r3,r1
0.830
-0.091
2.04
BLT |L1.12|
3.100
-0.200
2.04

至此,可以得出完整的简单插入排序函数的基于复杂度的嵌入式软件功耗模型
E=93.51-5.38n+10.67 2
3.3 基于复杂度的嵌入式软件功耗模型的估算功耗
当输入数组长度为n=80的情况下,通过该模型可快速估算出插入排序函数的功耗
E=93.51-5.38%26;#215;80+10.67%26;#215;1600=67924.85(nJ)
与指令级功耗模型的估测值误差小于1%(表6),而利用基于复杂度的功耗模型估测该函数执行所需的功耗的速度而大大提高。
表6 各种数组长度下简单插入排序指令级功耗
数组长度
指令级功耗模型估测
基于复杂度的功耗模型估测
误 差
n=10
1106.338
-
-
n=20
4252.333
-
-
n=40
16943.823
-
-
n=80
67604.803
67924.85
0.4%
4 总结
本文介绍了一种基于复杂度的嵌入式软件功耗模型,以对象函数的算法平均复杂度的建模参数,利用现有底层指令级功耗模型对函数进行分析,回归出必需的系数,得到该函数完整的基于复杂度的嵌入式软件功耗模型,从而可快速估算出该函数在不同输入情况下的软件功耗。这种分析方法的缺点在于只适用于算法复杂度明显的一些函数,从而较容易构建基于复杂度的模型。另外在建模过程中,仍然需要指令级功耗模型的分析法的协助。